CxHub客户体验社区-用户研究、体验爱好者学习交流社区,专注客户体验(CX)研究。
社交媒体
文/小只
许多事物之间的变化是相互影响的,这些联系通常可以通过一定的量化关系加以体现。
我们称之为依存关系。
依存关系一般可以分为两类:函数关系 and 相关关系。
函数关系:事物与其变量之间存在着明确、严格的依存性。
例如,利润等于收入-成本,这种情况下变量之间的关系是确定的,依赖于固定的计算规则。
相关关系:描述了一种相对不确定的数量联系。
在这种关系中,虽然某些变量的数值会影响到其他变量,但这种影响并非固定的,而是遵循一定的规律,在特定范围内波动。
例如,随着广告费用的投入增多,销售量会带来提升,但并不知道确切的提升数字。
而相关分析,翻译Correlation Analysis,是市场及用户研究中广泛应用的统计工具。
它为理解变量之间的关系提供了强大的支持,从简单到复杂的关系解析,相关分析无处不在。
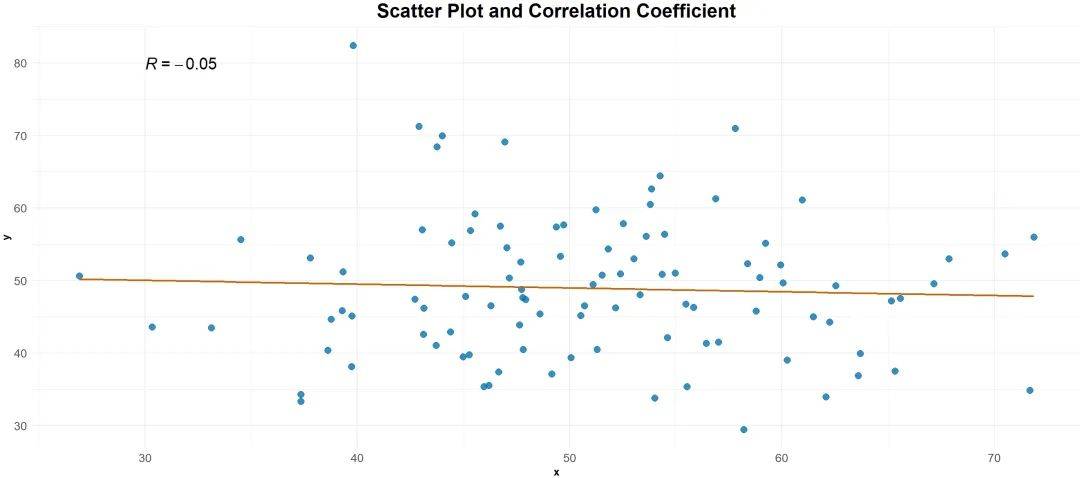
相关分析起源于19世纪末期,由卡尔·皮尔逊(Karl Pearson)和弗朗西斯·高尔顿(Francis Galton)等统计学家发展起来。
相关分析基于统计学中的协方差(Covariance)概念,它测量变量间的关系强度和方向。
它如何测量?
通过相关系数。
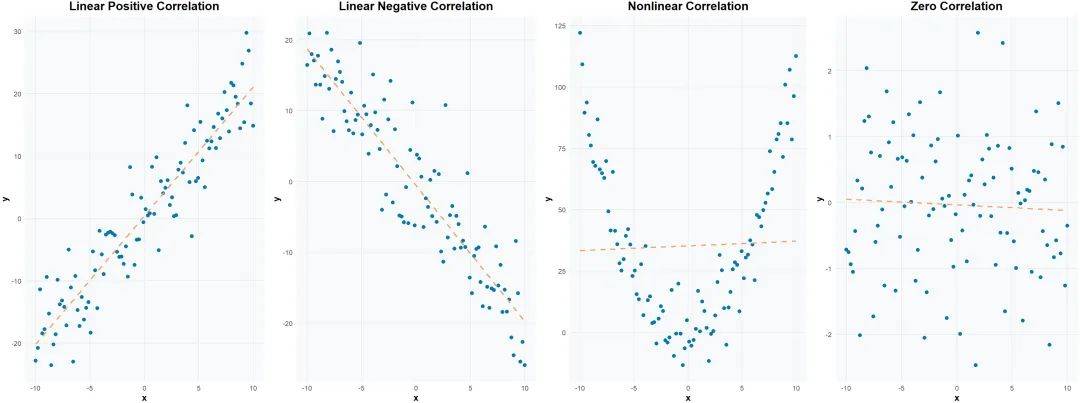
相关系数(Correlation Coefficient)是用来量化变量之间线性关系强度和方向的数值,通常用符号r表示。相关系数的取值范围是-1到1,其中:
① r = 1:表示两个变量之间有完全正相关。
② r = -1:表示两个变量之间有完全负相关。
③ r = 0:表示两个变量之间没有线性关系。
计算相关系数的方法有很多种,后续在方法介绍中会详细展开。
相关与因果
相关分析衡量的是变量之间的关系强度,而非因果关系。
因果分析通常需要通过实验设计或使用更复杂的模型(如回归分析)来验证。
相关与回归
回归分析是一种扩展的相关分析,它不仅探讨变量之间的关系,还用于预测。
相关系数可以看作回归分析中的一个组成部分,帮助确定变量之间的线性关系强度。
相关与协方差
协方差是相关分析的基础,表示两个变量的联动趋势。然而,由于协方差的度量受变量的单位影响,相关系数通过标准化协方差,提供了单位无关的度量,便于不同变量之间的比较。
① 皮尔逊相关分析
(Pearson Correlation)
应用范围:适用于连续变量之间的线性关系分析。
前提条件:
① 数据是连续型且近似正态分布。
② 变量之间存在线性关系。
注意事项:皮尔逊相关系数对异常值敏感,分析前需对数据进行清理。
② 斯皮尔曼等级相关分析
(Spearman's Rank Correlation)
应用范围:适用于有序数据或非正态分布的变量之间的单调关系分析。
前提条件:
① 数据可以排序(有序数据)。
② 不要求数据是线性或正态分布。
注意事项:斯皮尔曼相关系数适用于处理非线性关系,且对异常值不敏感。
③ 肯德尔相关分析
(Kendall's Tau)
应用范围:适用于小样本等级数据的相关性分析。
前提条件:
① 适用于处理有序数据。
② 适合小样本且对异常值不敏感。
注意事项:计算过程较为复杂,尤其在样本较大时,计算成本增加。
④ 偏相关分析
(Partial Correlation Coefficient)
概念:用于测量两个变量在控制了其他变量影响后的相关性。
这种方法帮助识别两个变量之间的纯粹关系,排除干扰因素的影响。
应用范围:常用于分析存在潜在混淆变量的市场数据,例如,研究广告效果时控制季节性因素。
使用前提条件:
① 需要明确控制变量,并确保它们确实是干扰因素。
② 数据需满足线性关系假设。
注意事项:偏相关分析的结果可能因控制变量的选择不同而变化,需谨慎解释。
⑤ 多元相关分析
(Multiple Correlation Analysis)
复相关是一种特殊的多元相关分析情况,集中在单个因变量上,而多元相关分析则可以包含复相关的情况,但也可以涉及更多因变量。
概念:研究多个自变量(独立变量)对一个或多个因变量(依赖变量)的综合影响。
使用前提:
① 各自变量之间无高度共线性。
② 适用于线性关系且数据分布正常。
③ 数据满足多元线性回归的假设。
注意事项:多元相关分析的解释难度较大,需谨慎解读各个变量的相对贡献。可以通过调整后的R²来评估模型的整体拟合度。
⑥ 典型相关分析
(Canonical Correlation Analysis)
概念:一种用来分析两个变量组之间(通常是一组自变量和一组因变量)的相互线性关系的统计方法。
其目的是寻找两组变量的线性组合,使得这些线性组合之间的相关性最大化。
是多元相关分析的一个子集,专门处理多个自变量与多个因变量之间的关系。
使用前提:
① 线性关系假设:基础假设是两组变量之间存在线性关系。
② 多变量正态分布:假设自变量和因变量都是来自多变量正态分布。
③ 变量的独立性:假设每组变量内的观测是相互独立的。
④ 样本量要求:要求较大的样本量。
⑤ 变量的数量匹配:过大的变量数量差异可能导致结果解释困难。
⑥ 变量的尺度和单位一致性:如果不同变量的量纲或取值范围差异较大,它们在CCA中的影响也会被放大或减弱。
⑦ 点二列相关分析
(Point-Biserial Correlation)
应用范围:适用于分析一个二元分类变量(如性别)与一个连续变量(如收入)之间的关系。
前提条件:
一个变量是二元分类,另一个是连续型且近似正态分布。
⑧ 二列相关分析
(Biserial Correlation Coefficient)
二列相关系数与点二列相关系数类似,不同的是,这种方法假定二分变量是人为分割的连续变量。它用于分析那些本质上是连续的,但由于某种原因被分类为两个类别的数据。
例如,测试成绩根据及格线被分为合格和不合格。
⑨ 菲系数分析
(Phi Coefficient)
应用范围:适用于两个二元分类变量(如是否购买产品与是否推荐产品)之间的相关性分析。
前提条件:
两个变量均为二元分类。
以上,但未穷尽,还有如非线性相关分析(Non-linear Correlation Analysis)等相关分析方法。
当两个变量之间的关系不是线性的,而是呈现曲线关系时,可以进行非线性相关分析。
① 相关性即因果性
很多人将相关性误认为因果关系。虽然两个变量可能显示出强相关性,但这并不意味着一个变量导致了另一个变量的变化。
例如,冰淇淋销量与溺水事件之间可能存在正相关,但真正的因果关系可能涉及天气因素,而非冰淇淋导致了溺水。
② 忽视数据质量
数据质量对相关分析的结果至关重要。异常值、数据噪声或缺失值可能会显著影响分析结果。
③ 忽略非线性关系
虽然皮尔逊相关系数测量的是线性关系,但许多变量之间可能存在非线性关系。
在这种情况下,使用斯皮尔曼或肯德尔相关系数等可能更合适。
④ 忽视模型的复杂性
在高级相关分析中,研究人员往往低估了模型的复杂性,尤其是在处理多个自变量和交互作用时。过度复杂的模型可能导致过拟合,从而降低模型的预测能力。
⑤ 仅关注相关系数的大小,忽略实际意义
在解释相关分析结果时,相关系数的大小虽然重要,但其实际意义更为关键。
例如,在商业应用中,即使相关系数不高,但只要有实际意义,仍应重视其结果。
SPSS:提供多种统计分析功能,如皮尔逊相关、斯皮尔曼相关等。
R语言:免费且强大,支持多种相关分析方法,并能轻松扩展功能。
Python:开源且灵活,可以通过Pandas、NumPy等库进行高效的数据处理和分析。