CxHub客户体验社区-用户研究、体验爱好者学习交流社区,专注客户体验(CX)研究。
社交媒体

系统聚类,又名谱系聚类、分层聚类、层次聚类,英文为Hierarchical Cluster。
将一组数据对象按照某种相似度度量标准进行分组。
形成一个树状的聚类层次结构,适合探索数据结构的层级关系。
可以对样本聚类也可以对变量聚类(SPSS中唯一1个可对变量聚类的聚类方法)。
层次聚类分为两种主要的方法:凝聚(自下而上,Agglomerative)和分裂(自上而下,Divisive)。
凝聚:将n个样品或变量看成n个分类,然后将距离接近的两类合并为一类,再从n-1类中继续寻找最接近的两类合并为一类,如此继续,最终将所有类别合并为一支,产生一个树状结构(聚类树或谱系图)。
分裂:则相反。
可以把层次聚类想象成朋友间的关系网。
凝聚层次聚类就像是在聚会上逐步建立朋友圈,从每个人独立存在开始,逐步找到关系最紧密的一对朋友,形成小团体,然后再找到关系紧密的团体继续合并,直到所有人形成一个大圈子。
分裂层次聚类则相反,从一个大圈子开始,逐步找到关系最疏远的小团体,将其分开,直到每个人单独分开。
① 聚类时应考虑多个连续变量间是否存在共线性影响,采用因子分析方法。
② 一般只用于数据样本数量在200以下。
① 不需要预先指定聚类数量。
② 层级关系直观:能够以层次结构的形式展示聚类结果。
③ 能处理各种形状的簇结构,包括非凸形状的簇。
④ 适用于各种数据类型:适用于数值型、分类型等各种数据类型。
数值型变量
可以直接使用常见的距离度量(如欧氏距离、曼哈顿距离)。
通常需要标准化以避免不同量纲的影响。
分类变量
需要转换为数值型表示或使用专门的距离度量方法。
将分类变量编码为数值型,如独热编码等。
有序变量
转换为数值型变量度量,或使用Gower距离。
将每个类别映射到一个数值,保留其顺序关系。
二元变量
可以直接使用二元距离度量方法。
无需特别预处理,二元变量可以直接使用。
混合变量
可以使用综合的距离度量方法,如Gower距离,该方法能够处理数值型、分类型和有序变量。
① 计算复杂度高:算法复杂度较高,处理大规模数据集时效率低下。
② 结果不唯一:不同的距离度量和簇间距离方法可能导致不同聚类结果。
③ 对初始样本顺序比较敏感,不同初始顺序可能导致不同聚类结果。
④ 噪声敏感:对数据中的噪声和异常值较为敏感,可能影响聚类结果。
① 选择距离度量和聚类方法:选择合适的相似度度量(如欧氏距离)和聚类方法(如完全链接)。
② 执行层次聚类算法:使用编程/统计工具实现层次聚类。
③ 结果分析:通过树状图分析数据对象的层级关系,选择合适的聚类数目。
④ 结果验证和评估:使用验证指标(如轮廓系数)评估聚类结果的质量。
Python:scikit-learn库中的AgglomerativeClustering类,SciPy库中的hierarchy模块。
R:hclust函数,pvclust包。
MATLAB:linkage和dendrogram函数。
SPSS。
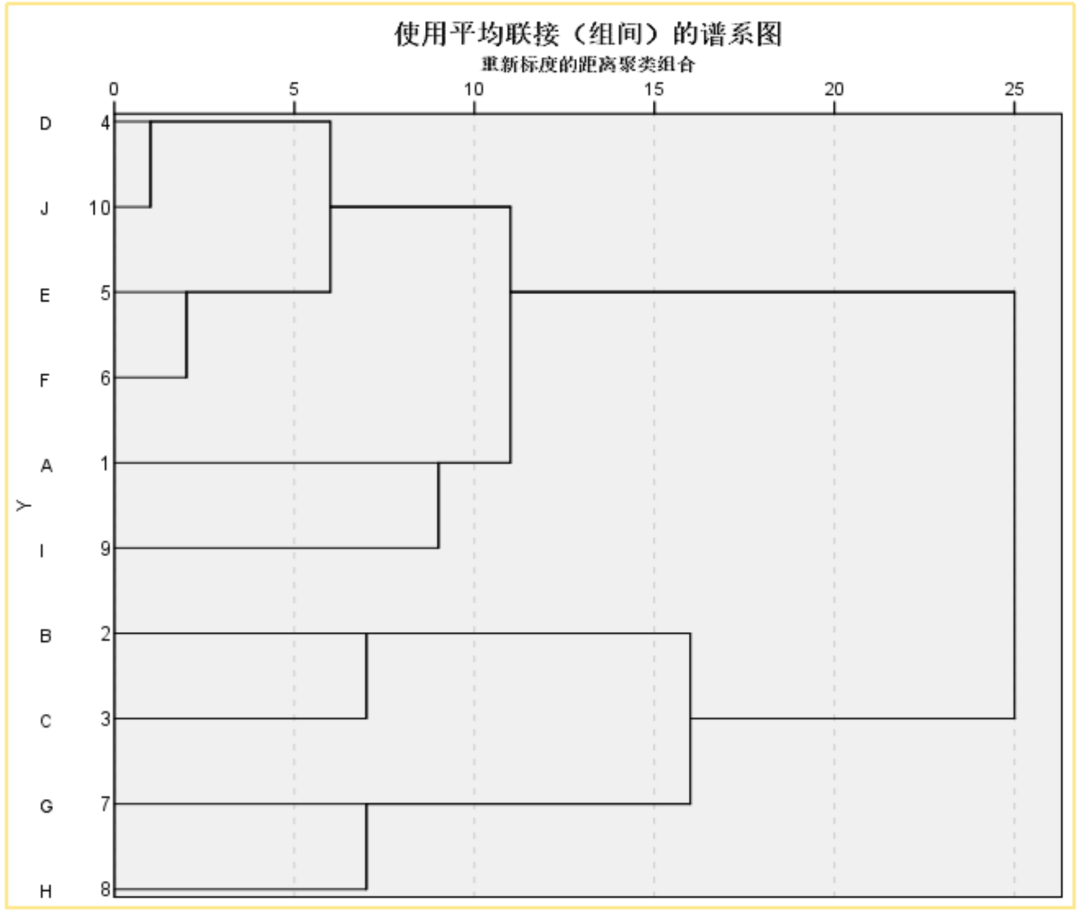
通过R实现了层次聚类的可视化,很清楚不同变量在不同聚类阶段的组合表现。
但不能直观看到聚成多少类比较合适。
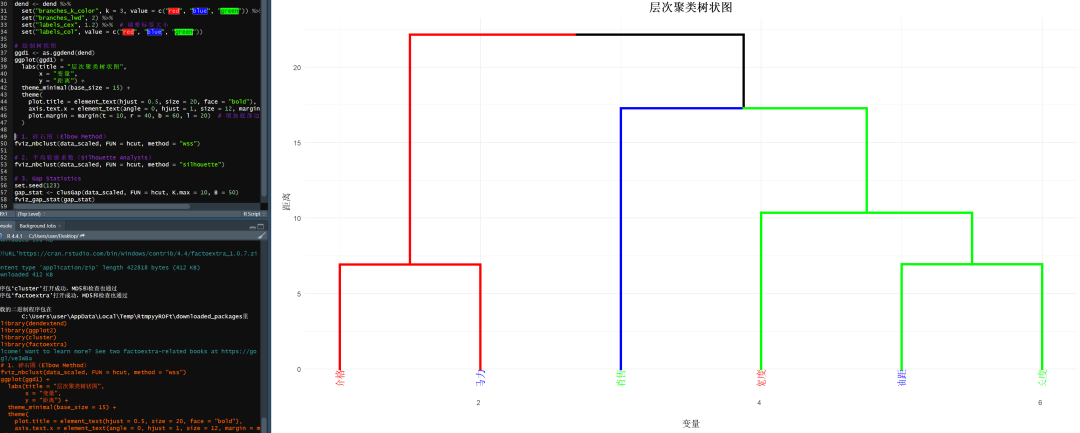
通过多种方法来参考判断。
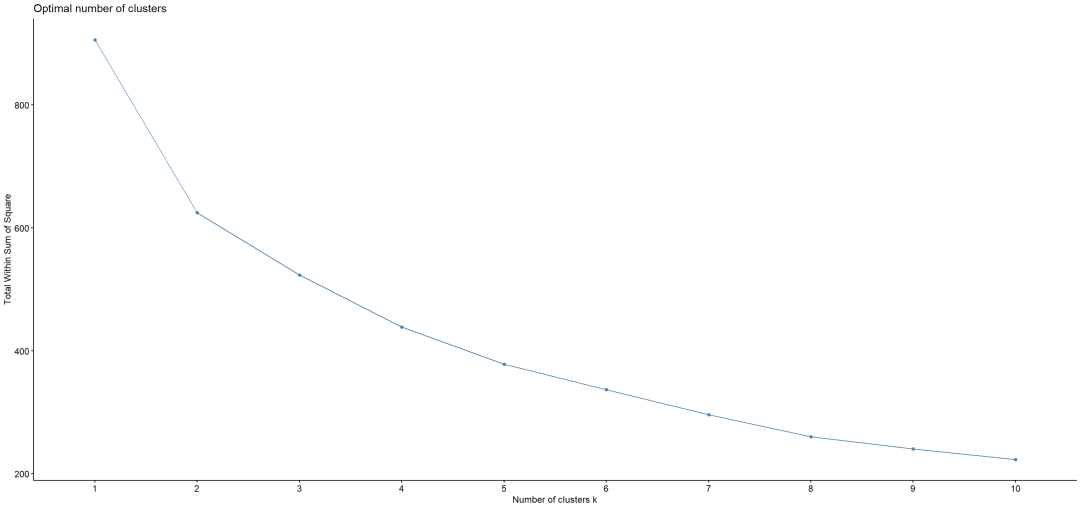
碎石图,看起来想是2类更合适。
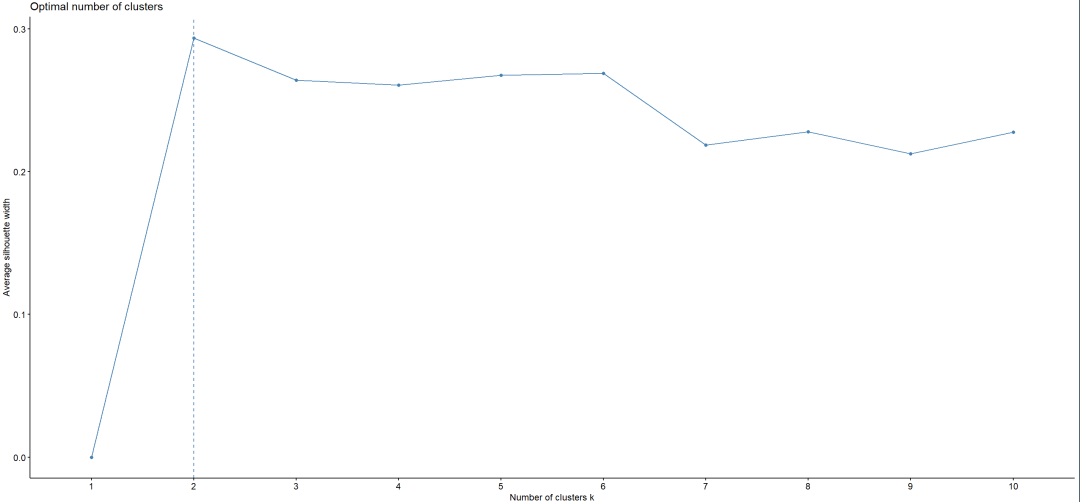
轮廓系数,2类最合适。
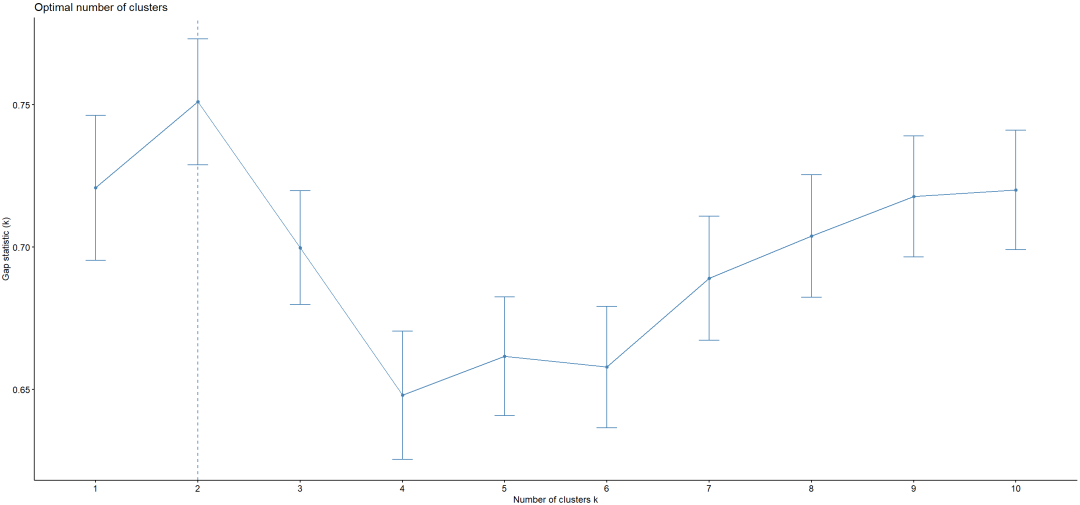
GAP统计值,2类更合适。
还有一个最直观的办法,就是观察。
如果在合并的过程中,有两个类的距离会有一个陡增,该类别个数有更大可能是适合的类别数量。
分析—分类—系统聚类
看研究目的:聚类样本or变量
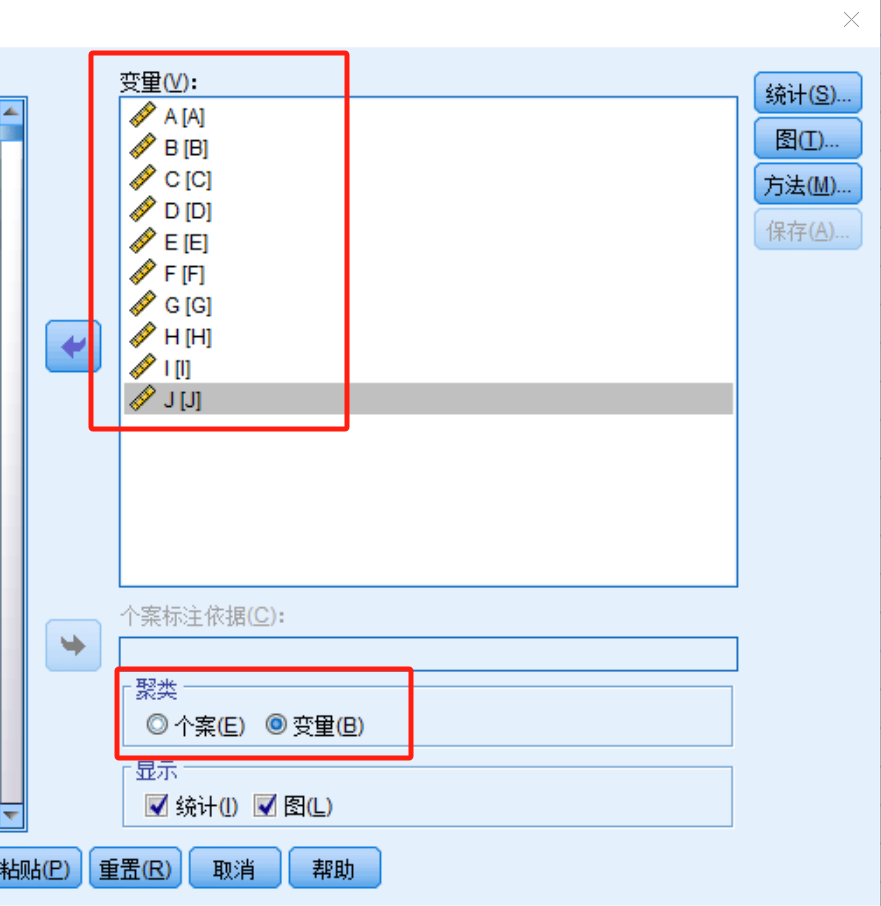
统计:
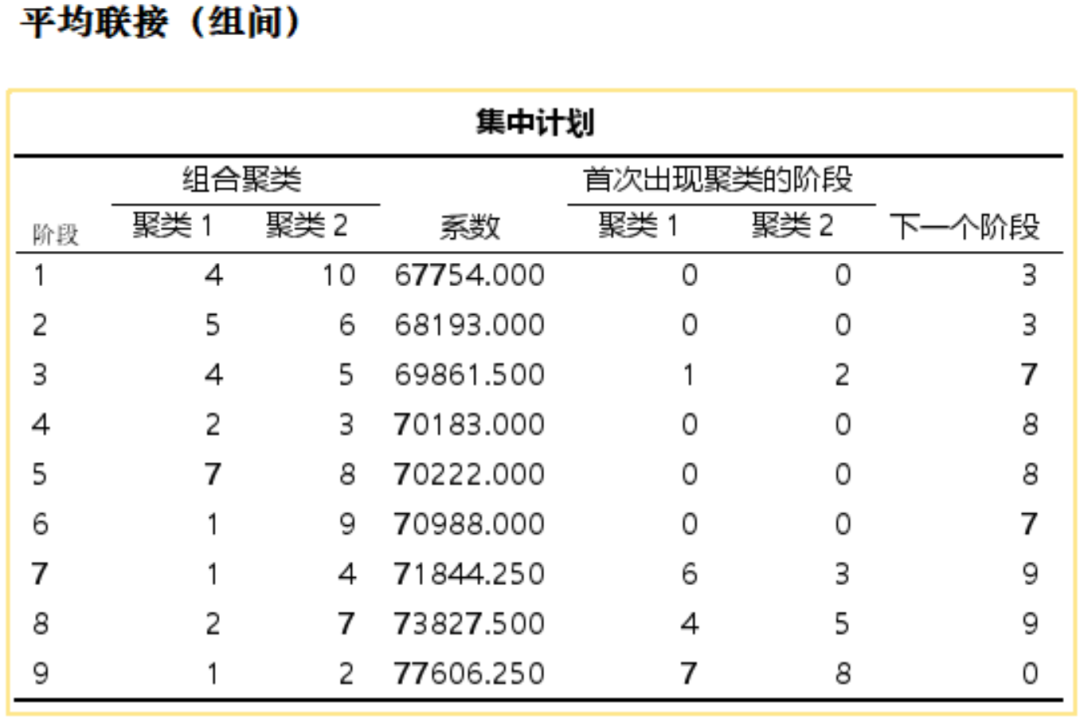
① 集中计划:是一个表格,记录了系统聚类过程中每一步合并(聚合)不同群组的细节信息,仅为聚类展示,可以不看。
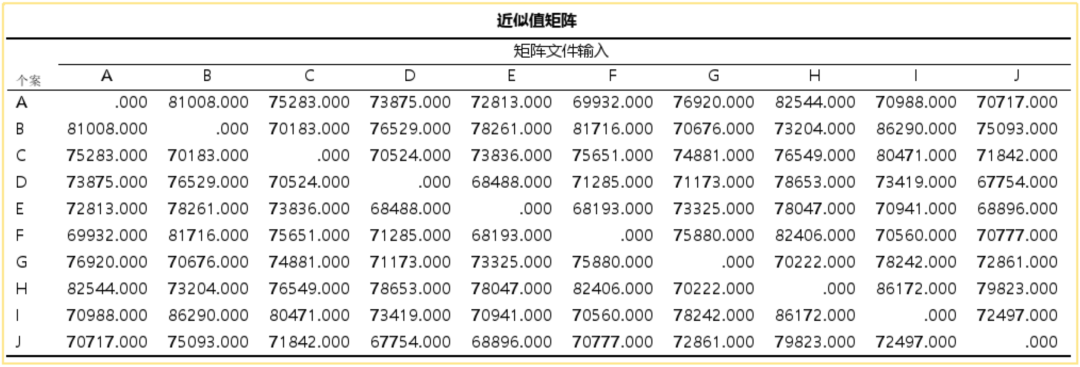
② 近似值矩阵:近似值矩阵显示了数据点之间的相似性或距离,通常以数值的形式呈现。
③ 聚类成员:一般不用特地设置,观察给出的树状图结论即可。
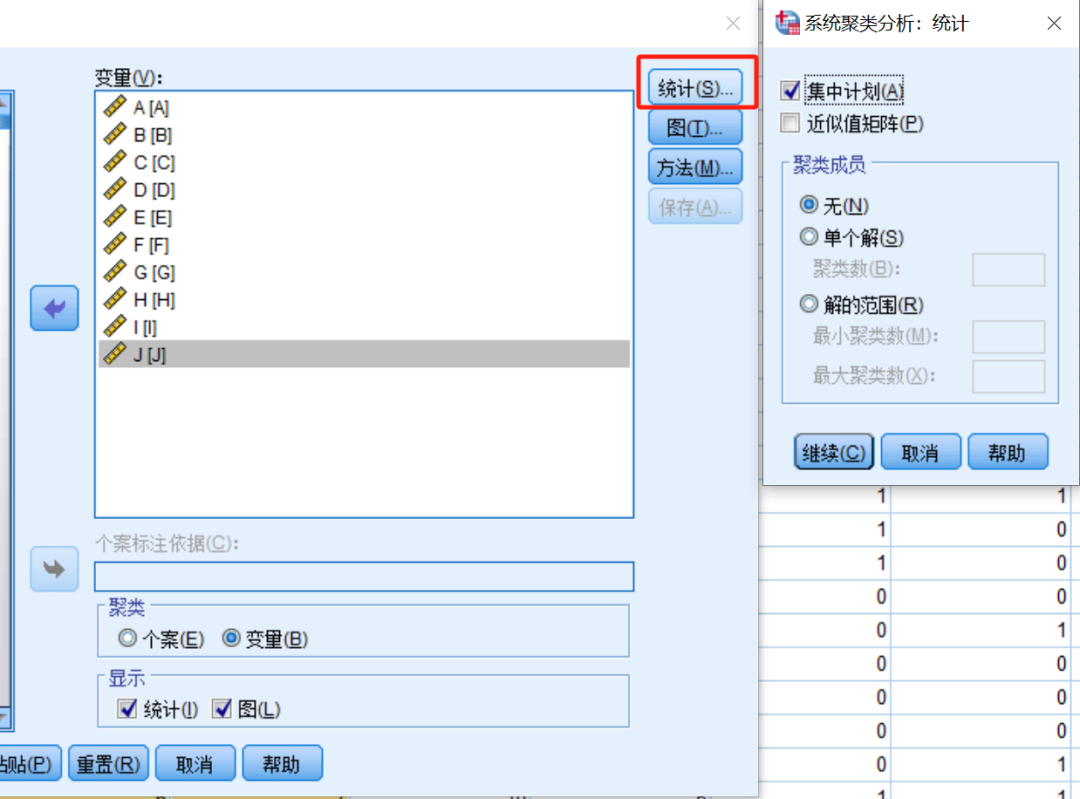
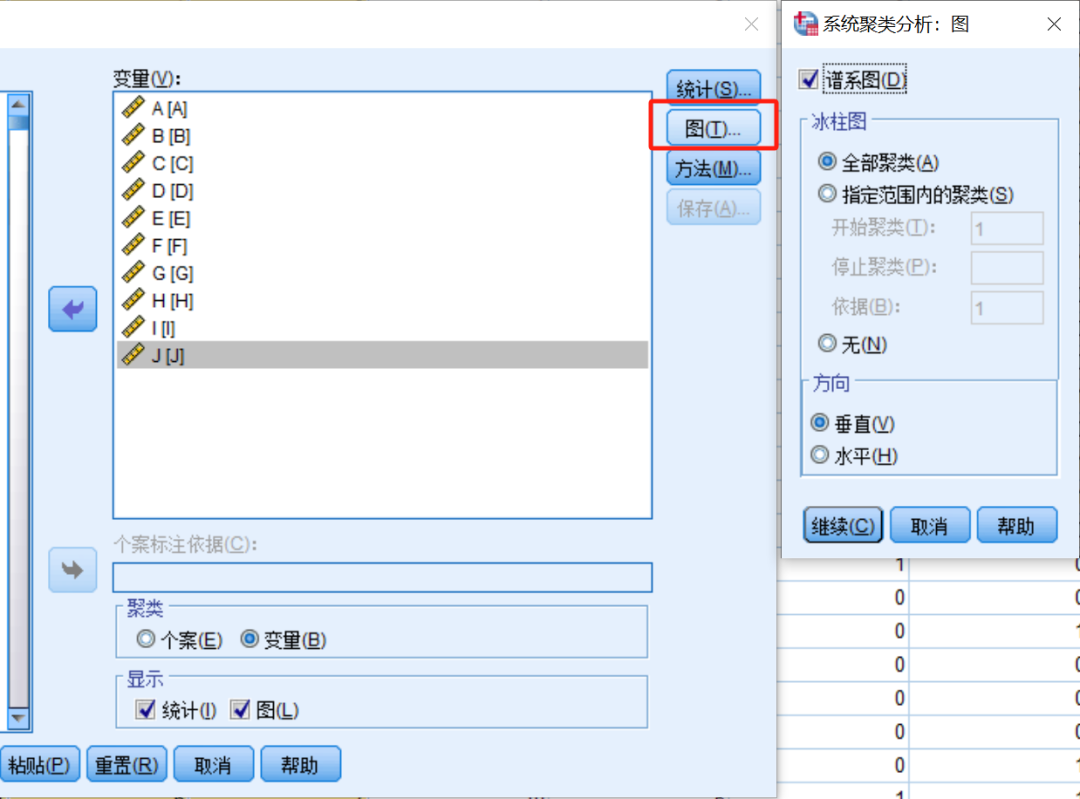
图:谱系图是聚类结果的可视化工具,用于展示数据点如何在聚类过程中分组。
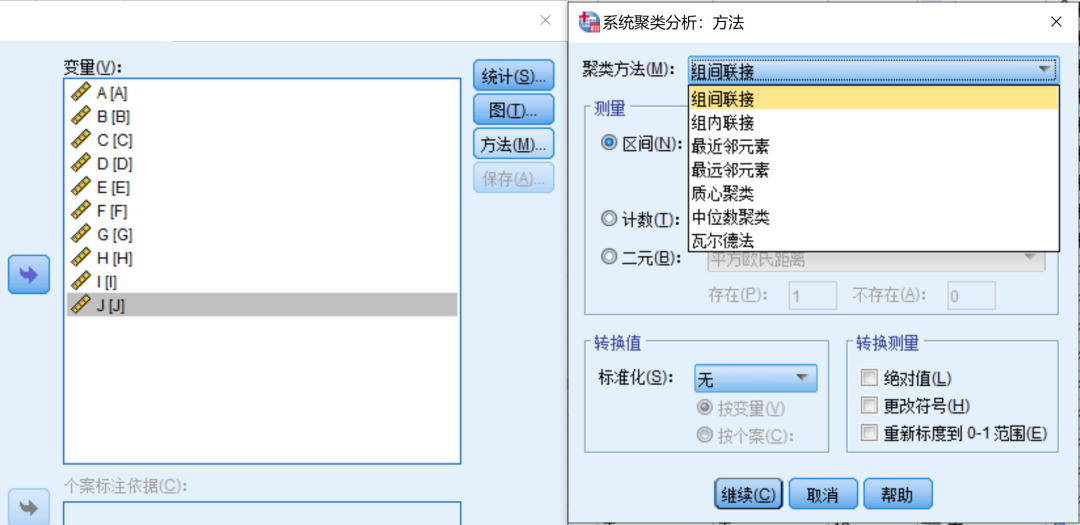
聚类方法:组间链接较为常用,是一种优秀而稳健的方法,保持默认较多。
组间链接(类平均法):是用两个类别间各数据点之间的距离的平均来表示两类别间距离。
质心聚类法:用两个类别的重心间的距离来表示两类别间距离。
最短距离法、中位数法和最长距离法:最短距离法是用两个类别中各数据点间最短的距离代表两类别间距离,最长距离法则正好相反,中位数法则介于两者之间。
组内联接法:首先在各类别中找到能使类别中各数据点间欧几里得平方距离的平均值最小的一点,然后计算这两点间的距离。
瓦尔德法(离差平方和法):在合并群组时考虑了群组的大小,并尽量保持新合并的群组与原始群组的方差之和的增加最小。
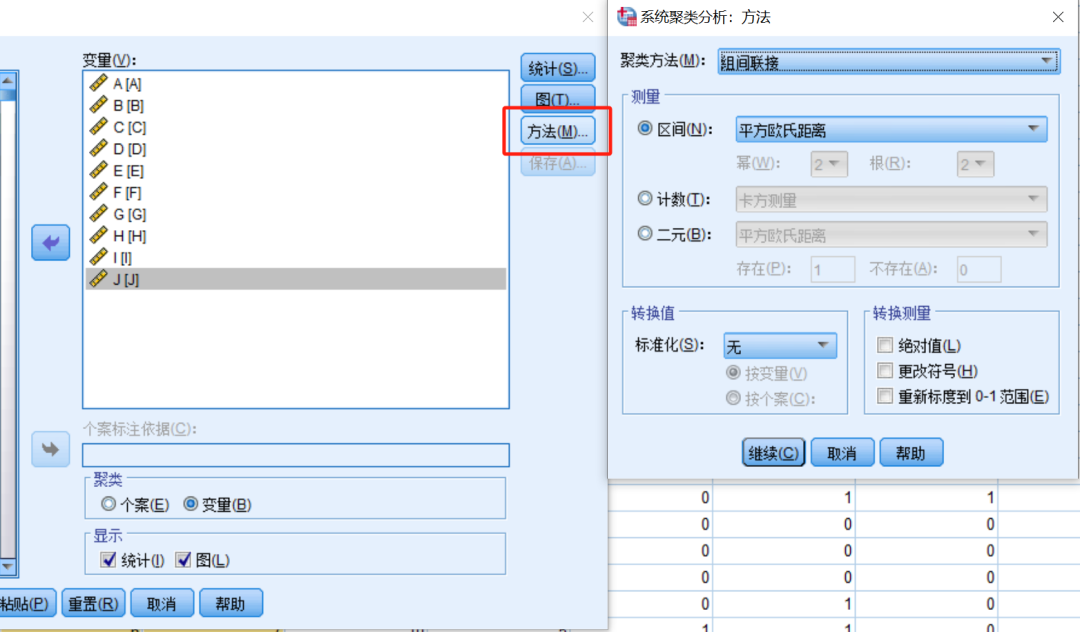
测量:根据变量的类型来选择
① 区间(Interval):连续变量
② 计数(Count):离散变量
③ 二元(Binary):二元变量
具体应该选取何种分析方法,视情况而定,但基本都可以尝试。
转换值&转换测量:如果变量有需要,可以进行数据标准化。
保存:当聚类类型是个案时,才会显示。
近似值矩阵:用于表示每个个体(或观测值)之间的相似度或距离。通常,相似度越高,则这两个个体之间的距离越近。
集中计划:="聚类中心",是指每个聚类群组的中心点,即群组中所有个体的平均值向量。
谱系图:可以更加形象地展示聚类的结果。
聚成多少类比较合适?
没有绝对准则,考虑对分类类别做(单因素)方差分析or类别与各属性的交叉表,来判定哪种聚类结果最佳。
(考察sig值是否显著)
也可参考R实践的检验方法。