CxHub客户体验社区-用户研究、体验爱好者学习交流社区,专注客户体验(CX)研究。
社交媒体

这一章就来讲讲最后一part,关于联合分析的实操。
因为没有具体的案例数据可以展示,所以只能尝试着尽量还原操作实践过程,同时把相应可能遇到的问题提出来。
不能作为操作手册,也可以辅助作为实践指南。
以手机为例,以下是详细的步骤及分析说明。
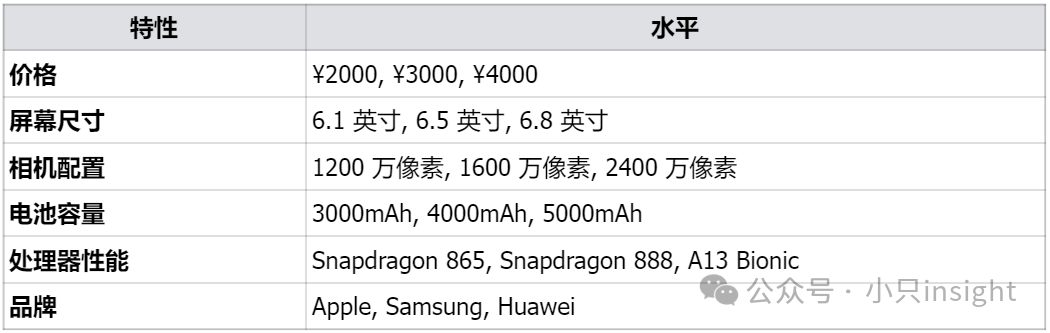
联合分析的第一步是选择你需要分析的产品特性以及它们的水平。
在确定产品特性时,应该避免选择过多的特性,因为这会使得分析变得过于复杂且难以实施。通常选择4-6个特性,每个特性包含3-4个不同的水平。
在手机行业中,常见的产品特性包括价格、屏幕尺寸、相机配置、电池容量、处理器性能等,每个特性都应该设置一定的水平。
示例:
联合分析的关键在于生成实验设计,即选择合适的特性组合呈现给受访者。
常见的设计方法有3种:
方法1:全析取设计(Full-Profile Design)
全析取设计列出所有特性组合(所有可能的配置)。
例如,如果有5个特性,每个特性有3个水平,则总共有3的5次方=243种不同的组合。
缺点:组合数可能会非常庞大,导致调查时间过长,受访者疲劳。
方法2:部析取设计(Partial-Profile Design)
每个问题中只展示部分产品特性,而不是所有特性。
这种设计方法的目的是减少受访者的认知负担,使得每次选择任务的复杂性降低。
例如:
第一道题展示特性组合 {价格、相机配置、电池容量}。
第二道题展示特性组合 {屏幕大小、价格、品牌}。
换句话说,它是一种问卷呈现策略,用来减少每道题目中展示的特性数量。
方法3:正交设计(Orthogonal Design)
跟前两者的关系:它既可以用于 全析取设计 也可以用于 部析取设计 中生成代表性组合,结合使用。
它是一种用于 实验设计 的方法,旨在通过 最少数量的实验组合 来最大化地提取产品特性(属性)和特性水平(水平)的影响信息。
在联合分析中,正交设计被广泛使用,以减少问卷中需要展示的产品配置数量,同时保证实验结果的统计效力。
总而言之,提高效率、减少受访者疲劳,同时保证统计效力。
简单示例
假设我们研究一种手机的市场偏好,需要分析以下 3 个特性,每个特性有 2 个水平:
价格:高价、低价;颜色:黑色、白色;屏幕尺寸:大屏、小屏
如果我们采用 全析取设计,所有可能的产品组合为:
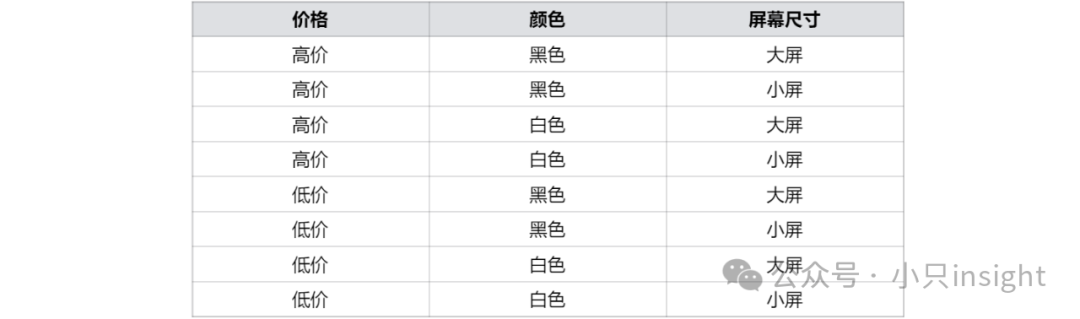
共计2的3次方=8种组合。
使用 正交设计 时,我们可以选取一部分最具代表性的组合,如下所示。

通过这 4 个组合,我们依然能充分分析每个属性和水平对用户偏好影响,而不需要展示所有 8 个可能的组合。
另外还有自适应设计、拉丁方设计(下文会提及)、随机设计(简单)等方法,此处不再做展开。
具体工具生成步骤(不做详细展开):
SPSS:详细可在电脑端点开此链接,里面有详细步骤,此处不做重复展示。
https://spss.mairuan.com/jiqiao/spss-jdiowle.html
Sawtooth:专业生成实验设计的软件,可以灵活选择全析取或部分析取设计。
R / Python:使用 AlgDesign(R)或 pyDOE(Python)生成拉丁方设计。
问题一:选项怎么得出?
前面提到通过如正交设计的方式得出了产品组合,那下一步是如何把这些组合合理地放到问卷中。
有两种思路:
(全析取设计被我抛弃了,部析取设计就以正交设计为例)

问题二:选项怎么组合?
(这个问题是联合分析成败的关键,所以篇幅内容会较多)
表面上看,如果正交设计生成了 30 个组合,而我们确实要把它们分配到 10 个问题中,每个问题展示 3 个组合,最终所有的组合都会被用到。这种情况下,是否还需要考虑均衡分布?直接随机分组不就可以了吗?
有很高的风险,理由如下:
1.属性水平的均衡性
即使组合整体均衡,随意分组可能破坏单个问题中的均衡性,使得部分问题对分析无用。
假设有一个属性是“价格”,包含 ¥2000、¥3000 和 ¥4000 3 个水平。
在某次随机分组中,可能出现 3 个组合的价格全是 ¥2000。这会导致这一题对受访者来说毫无意义,因为没有任何差异化选项。
2.顺序效应
受访者在回答问题时,可能受到选项位置的影响(顺序效应)。
如果一个特定组合总是出现在第一个位置,那么它的选择频率可能偏高,而这并非反映消费者的真实偏好,而是受顺序影响。
解决方案是什么?引入拉丁方设计。
拉丁方设计(Latin Square Design) 是一种实验设计方法,旨在通过优化排列和分组,确保实验中每个组合或每个特性水平在不同条件下均衡分布。这种方法通常与正交设计、部析取设计结合使用。
简单来说,它是一种行-列均衡的实验设计的 n×n 的正方阵,满足:
① 每个元素在每行和每列中仅出现一次。
② 每个组合的排列顺序均匀分布。
分配结果示例
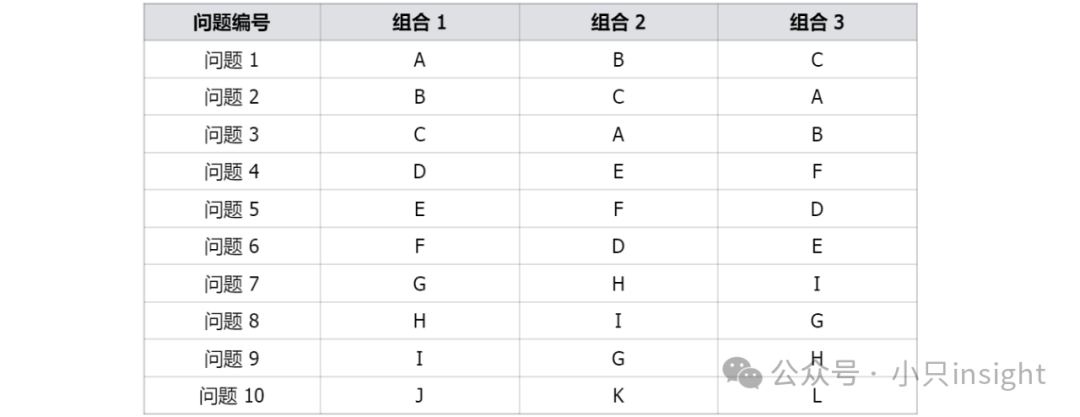
通过拉丁方设计,可以确保2个关键点:
① 组合在问题中的均衡出现
每个组合的出现频率相同(例如每个组合都恰好出现 1 次)。
每个问题中的属性水平均匀分布,不会出现无意义的重复选项。
② 控制组合的排列顺序
每个组合在不同问题中以不同的位置出现,避免顺序效应。
受访者对所有组合的偏好评估更加公平,结果更可靠。
换句话说,正交设计+拉丁方设计的组合应用能最大程度地降低后期数据分析风险。
用一张表来总结展示:

问题三:题目如何设置?
设计一个包含多个选择题的问卷,每个问题呈现一定数量的产品组合,通常为 3-5 个配置,受访者需要选择他们最偏好的选项。
常见问题类型:
CBC:每个问题给出多个选项,受访者选择最喜欢的配置。
BWS:每个问题要求受访者选择“最喜欢”和“最不喜欢”的配置。
成对比较:每次比较两个选项,受访者选择一个更偏好的配置。
问卷示例:
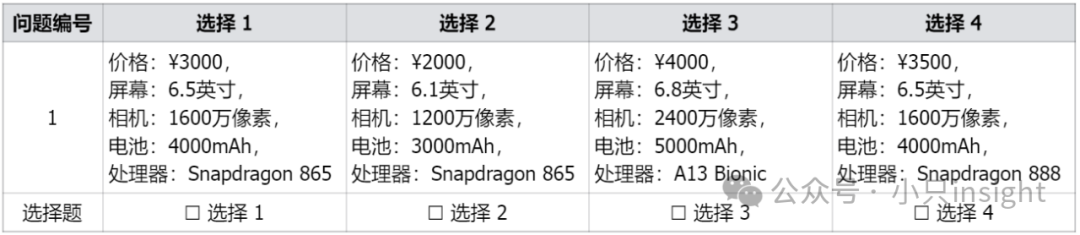
收集平台:如问卷星、SurveyMonkey、Qualtrics等。
填答容量:每个受访者需要回答 15-20 道问题,至少 200 名受访者以上,确保数据稳定。
一张表先做总结,有兴趣可往下阅读展开。
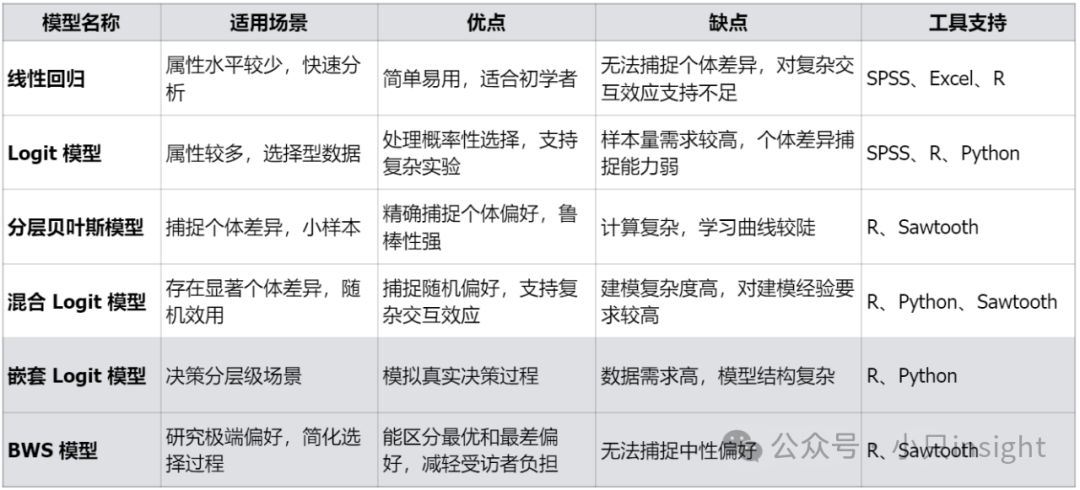
1.1 基本模型
(1)线性回归模型
原理:基于最小二乘法估计效用值,假设每个属性水平对总效用的贡献是线性可加的。
适用场景:属性和水平数量少;个体间差异不大;初学者快速分析。
优点:简单易用,计算速度快。
缺点:不能捕捉个体差异;对于复杂交互效应支持不足。
(2)Logit 模型
原理:基于最大似然估计,适合离散选择数据,计算消费者选择某个组合的概率。
适用场景:属性较多,受访者选择数据为“选择-未选择”格式。
优点:能够处理概率性选择,支持复杂实验。
缺点:个体差异捕捉能力较弱;样本量需求较高。
1.2 进阶模型
(3)分层贝叶斯模型
原理:通过贝叶斯统计框架,在群体层面和个体层面同时估计效用值。
适用场景:需要捕捉个体偏好差异;样本量相对较小;复杂属性结构。
优点:精确捕捉个体差异;鲁棒性强,适合小样本。
缺点:计算复杂,学习曲线较陡。
(4)混合 Logit 模型
原理:通过引入随机效用,允许消费者的选择偏好在样本中具有分布特征。
适用场景:存在显著的个体差异;需要分析随机偏好和交互效应。
优点:捕捉个体偏好差异;支持随机效用。
缺点:计算复杂度高;对建模经验有较高要求。
如何选择适合的模型?
模型选择取决于以下因素:
①数据类型
选择型数据(如 CBC 数据):推荐 Logit 模型、混合 Logit 模型、分层贝叶斯模型。
最优-最差数据(如 BWS 数据):推荐 BWS 模型。
连续型数据(如效用值):推荐线性回归。
②分析目标
捕捉群体偏好:Logit 模型、线性回归。
捕捉个体差异:分层贝叶斯模型、混合 Logit。
模拟复杂决策:联合多项 Logit、嵌套 Logit。
③数据复杂性
属性和水平数量少:线性回归。
属性和水平数量多:分层贝叶斯、混合 Logit。
④样本量大小
样本量较大(100+):Logit、混合 Logit。
样本量较小(<50):分层贝叶斯模型。
以SPSS为例,做一些简单的铺开,具体R和python的代码技术细节不做展开了。
① 打开 SPSS,选择 File → Open → Data 导入 CSV 文件。
② 确保数据列包含每个配置的特性(如价格、屏幕尺寸等),以及受访者的选择。
③ 在菜单中选择 Analyze → Conjoint,根据数据选择适当的模型(如 HB)。
④ 点击 OK 后,SPSS 会生成每个特性和水平的效用值,结果可以通过表格查看。
但SPSS需要高阶版本才能有此模块,详细情况可查阅IBM SPSS的官网。
用一张表先做总体呈现。
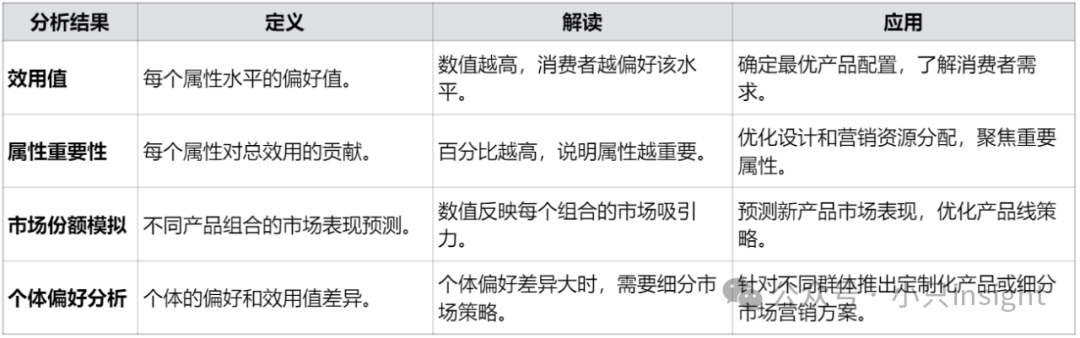
核心指标展开如下:
(1)效用值
定义:每个属性水平的效用值反映消费者对该水平的偏好程度。效用值可以是正、负或零。
解读:效用值越高,说明消费者对该水平越偏好;效用值的相对大小比绝对大小更重要。
(2)属性重要性权重
定义:属性重要性反映每个属性对总效用的贡献,占比用百分比表示。
计算公式:

解读:属性重要性越高,说明消费者越在意该属性。
(3)市场份额模拟
定义:基于效用值预测不同产品组合的市场份额。
解读:模拟在多种产品组合竞争时,各组合的市场占有率。
数据结果应用

在价格研究的场景下,可以横向对比PSM、Gabor-Granger的方法差异,之后的系列文章会提到。
常见工具及功能支持,如下表格:
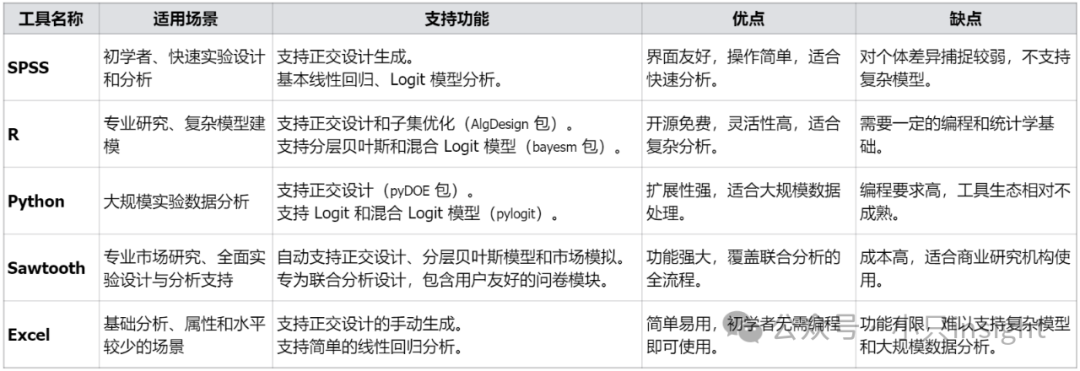
前面在诸多步骤中均提到了Sawtooth,这里再展开啰嗦一下。
Sawtooth本身不具备直接投放问卷和触达消费者的功能,它的主要功能是用于设计联合分析实验、生成问卷以及对收集到的数据进行分析。
Sawtooth官网在此:https://sawtoothsoftware.com/
一般的工作流是Sawtooth + 其他工具。
Step 1: 使用 Sawtooth 设计问卷
① 在 Sawtooth 中创建联合分析实验。
-定义产品特性和水平。
-选择实验设计类型(如 CBC、ACA)。
-自动生成选择题并预览问卷。
② 将设计好的问卷导出为在线链接。
Step 2: 使用第三方平台投放问卷
将 Sawtooth 的问卷链接嵌入到 SurveyMonkey、问卷星 或其他平台,利用这些平台投放问卷。
Step 3: 数据收集
将第三方平台的数据导入 Sawtooth 进行分析。
Step 4: 数据分析
① 使用 Sawtooth 分析模块计算效用值、市场份额预测。
② 或将数据导出到 SPSS、R、Python 中进行深度分析。
参考文献:
Green, P. E., & Srinivasan, V. (1978). Conjoint Analysis in Consumer Research: Issues and Outlook. Journal of Consumer Research.
Orme, B. (2010). Getting Started with Conjoint Analysis: Strategies for Product Design and Pricing Research. Research Publishers LLC.
SPSS Documentation. (2022). Conjoint Analysis in SPSS. SPSS Inc.
Sawtooth Software. (2021). The Conjoint Analysis Handbook. Sawtooth Software.
Green, P. E., & Wind, Y. (1973). *New ways to measure consumer preferences*. Sage Publications.
Johnson, R. M., & Orme, B. (1996). *Conjoint analysis applications in marketing: A guide to new techniques and real-world problems*. Sage Publications.
Train, K. E. (2009). *Discrete choice methods with simulation*. Cambridge University Press.