CxHub客户体验社区-用户研究、体验爱好者学习交流社区,专注客户体验(CX)研究。
社交媒体
本文将为大家系统解析一篇题为《利用深度学习和多模态大型语言模型理解自然面部表情》的综述文献。
该研究聚焦人工智能技术在情感计算领域的革命性突破,通过整合深度神经网络(DNN)的细粒度特征提取能力与多模态大型语言模型(MLLM)的语义推理优势,重构了自然场景下面部表情的识别范式。
文章不仅对比了五类前沿工具的算法架构与技术特性,更前瞻性地提出“上下文嵌入情感模型”(Context-Embedded Affective Model)的理论框架,为突破传统实验室研究的生态效度困境提供了新路径。

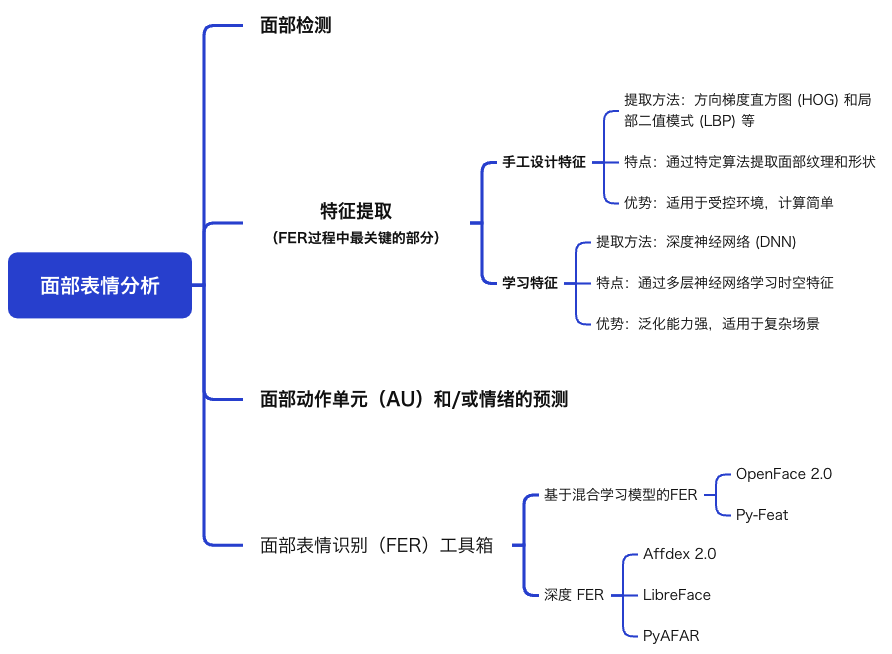
环境干扰
自然情境中面部表情常伴随光照变化、头部姿态多样、面部遮挡(如眼镜、手势)等,传统FER模型(如基于HOG/LBP的手工特征)难以稳定检测。
解决方案:深度学习模型(如CNN、ViT)通过大规模野生数据训练,提升鲁棒性。
情感解释的复杂性
实验室数据可通过自我报告验证情感,但自然数据需依赖多模态上下文(如场景、语音、身体语言)推断心理状态。
核心矛盾:单纯依赖面部特征可能导致误判(如“微笑”可能表达快乐或讽刺)。
表 1:FER 工具箱在功能、神经架构和用于训练情感或 AU 模型的数据集类型方面的比较
深度学习模型以粗体显示。
数据集分为 W(wild)、S(spontaneous)或 P(posed),分别代表来自互联网或非实验室环境、由实验程序诱导或由实验室环境中的演员故意模仿的面部表情。
* 请参阅网站以获取 Py-Feat 中包含的所有人脸检测模型的完整文档。
** Affdex 2.0 的情感模型未指定,因为它基于 AU 的激活。
*** 用于在 Affdex 2.0 中训练 AU 模型的数据集被认为是自发的,尽管是在非实验室环境中捕获的。
OpenFace 2.0 | Py-Feat | Affdex 2.0 | LibreFace | PyAFAR | |
Face Detection | CE-CLM | MTCNN, RetinaFace * | R-CNNs | MediaPipe | MediaPipe, Facenet |
Emotion Recognition | ResMasNet, SVM | ** | ViT, ResNet-18 | ||
Action Unit | SVM, SVR | SVM, XGB | CNNs | ViT, ResNet-18 | ResNet-50 |
Datasets | P, S | P, S, W | S *** | S, W | S |
Open Source/Free | Yes | Yes | Yes | Yes | |
Graphical User Interface | Yes | Yes | Yes | Yes | |
Website | github.com/TadasBaltrusaitis/OpenFace (accessed on 29 November 2023) | py-feat.org (accessed on 29 November 2023) | www.affectiva.com (accessed on 29 November 2023) | github.com/ihp-lab/LibreFace (accessed on 29 November 2023) | affectanalysisgroup.github.io/PyAFAR2023 (accessed on 29 November 2023) |
核心技术:
混合模型:深度卷积专家约束局部模型(CE-CLM)用于面部特征检测,HOG特征+SVM/SVR算法实现AU检测。
训练数据:实验室数据集为主(Bosphorus、CK+、DISFA等)。
适用场景:实验室环境下AU检测与姿态估计(如静态表情分析)。
优势:
开源免费,支持多任务(注视、姿势、AU检测)。
对侧面/遮挡人脸的检测优于早期版本。
局限性:
野生数据泛化性差(Aff-wild2数据集F1值仅0.61)。
头部角度>45°时性能骤降(误差增加30%)。
核心技术:
灵活架构:MTCNN/RetinaFace检测,ResMasNet(残差掩蔽网络)+XGB分类。
训练数据:混合实验室(BP4D、CK+)与野生(Aff-wild2)数据集。
适用场景:动态视频表情分析(支持时间序列统计)。
优势:
跨姿态鲁棒性强(头部角度变化下误差仅±5%)。
注意力机制优化遮挡处理(AffectNet准确率68%)。
局限性:
无图形界面,需Python编程基础。
实时性不足(处理速度<15fps)。
核心技术:
商业闭源模型:R-CNN检测,CNN优化跨种族AU识别。
训练数据:私有野生数据集(1100万张图像,覆盖多年龄/种族)。
适用场景:商业用户体验分析(广告、产品测试)。
优势:
跨种族偏倚低(非洲/南亚人群识别误差<8%)。
适应复杂环境(如光照变化、遮挡)。
基于EMFACS规则推理复合情绪(如困惑=AU4+AU7)。
局限性:
未公开跨库验证结果(DISFA性能存疑)。
高授权成本,无法二次开发。
核心技术:
前沿架构:Swin Transformer全局建模,MAE自监督预训练。
训练数据:大规模野生数据集(AffectNet、FFHQ)。
适用场景:复杂环境下的实时分析(光照变化、遮挡场景)。
优势:
高性能(AffectNet情感识别准确率75%)。
轻量化设计(计算负载较传统ViT降低50%)。
局限性:
依赖MediaPipe的468点面部配准,部分移动端兼容性差。
预训练数据存在西方文化倾斜(东亚样本<15%)。
核心技术:
双模型架构:ResNet-50+MediaPipe,专精跨年龄段AU检测。
训练数据:成人(BP4D+)、婴儿(MIAMI、CLOCK)。
适用场景:婴幼儿情感行为研究(如自闭症早期筛查)。
优势:
婴儿AU检测首创(9种婴儿专属AU)。
动态跟踪能力强(个体离场后重识别率>90%)。
局限性:
需特定标注数据(如BP4D+的主动/被动任务)。
成人模型仅支持12种基础AU。
MLLM(Multimodal Large Language Model) 是一种基于深度学习的人工智能模型,能够整合并理解文本、图像、语音、视频等多模态数据,通过跨模态对齐和语义推理,实现复杂任务的上下文感知与决策。
跨模态对齐:整合面部表情、场景、语音、文本等多模态信号(如通过LLaVA分析“滑雪场景下的举手动作”推断“快乐”而非“恐惧”)。

该模型可以识别“兴奋”情绪与“在空中荡秋千”活动之间的关联,但它错误地将该人描述为戴着黑色头盔。
提示:“描述一下这幅图像?根据上下文可以推断出什么情绪?”
LLaVA-7B:“图像中有一个女人穿着橙色背心,戴着黑色头盔,悬挂在绳子或电线上。她在空中荡秋千时看起来很开心,可能是在荡绳索秋千或高空滑索。女人的微笑和戴着头盔的事实表明她正在享受一段有趣而冒险的时光。当女人沉浸在活动的刺激中时,这个场景传达出一种兴奋和喜悦的感觉。”
动态修正能力:结合上下文(如“婚礼现场”与“持枪画面”)修正情感解释,避免传统FER工具的静态标签误判。
混合情感分析:支持复合情绪识别(如“51%愤怒+49%厌恶”),突破传统“单一标签”限制。
跨文化泛化:通过少样本学习(如输入10张“面子文化”相关表情示例)适应文化特异性表达。
归因生成:提供情感推理的因果链(如“睁大双眼→恐惧情绪,伴随手部遮挡→抑制尖叫”)。

提示:“婴儿脸上流露出什么情绪?使用哪些特定的面部线索来推断情绪?”
LLaVA-7B:“婴儿的脸上流露出各种情绪,包括悲伤、恐惧,可能还有不适。婴儿的面部线索包括皱眉表情、眼中含泪和微微撅起的嘴巴。这些线索表明婴儿正在经历负面情绪或不适,可能是由于他们周围的情况或环境造成的”。
结合面部表情(FER工具检测)、语音语调(如音高分析)与场景文本,识别复合情绪(如“强颜欢笑”)。
案例:通过患者视频对话中的微表情与语音停顿,辅助抑郁症诊断。
动态调整机器人响应策略。例如:根据用户皱眉表情+“我没事”的文本矛盾,触发安慰性反馈。
案例:教育机器人识别学生困惑表情,自动调整教学节奏。
验证情感建构理论(如情境如何动态塑造表情感知)。
文化偏差:主流数据集(如AffectNet)中非西方样本占比不足10%,导致模型对东亚“含蓄表情”误判率增加25%。
标注噪声:互联网来源数据隐含意识形态偏见(如将“抗议”与“愤怒”强制关联)。
黑箱逻辑:MLLM可能生成错误归因(如将“瞳孔放大”归因于“兴奋”而非生理刺激)。
动态建模不足:对微表情时序演变(如0.5秒内从“冷笑”转为“愤怒”)捕捉精度低于40%。
监控滥用:结合面部识别与情境分析的MLLM可能侵犯隐私(如通过办公室监控推断员工情绪状态)。
构建“FER特征提取→MLLM情境推理”混合架构,平衡实时性(如30fps视频处理)与计算开销。
开发跨文化多模态基准数据集(如包含100万+非西方场景的“全球情感图谱”)。
建立“人类-AI协同”评估标准,强制要求MLLM输出可追溯的推理路径。
01 FER(Facial Expression Recognition)
定义:通过计算机视觉技术自动识别面部表情对应的情感类别(如快乐、愤怒)。
核心任务:检测动作单元(AU)、情感分类、强度估计。
02 AU(Action Unit)
定义:基于面部动作编码系统(FACS),描述面部肌肉运动的原子单位(如AU12=嘴角上提)。
作用:客观量化表情,避免情感标签的主观性。
03 生态效度(Ecological Validity)
定义:实验环境与真实情境的一致性。实验室表情可能缺乏自然动态性(如自发 vs. 表演)。
04 CNN(卷积神经网络)
特点:通过局部卷积核提取空间特征,适合处理图像局部模式(如眼睛、嘴部)。
代表模型:ResNet(残差网络)通过跳跃连接解决梯度消失问题。
05 ViT(Vision Transformer)
特点:将图像分割为块(patch),通过自注意力机制捕捉全局依赖关系。
优势:对复杂背景和遮挡更鲁棒(如LibreFace的Swin Transformer)。
06 知识蒸馏(Knowledge Distillation)
定义:将大模型的知识迁移到轻量级模型,平衡性能与计算效率(如LibreFace的轻量化设计)。
07 AffectNet
规模:100万+野生图像,标注情感类别(8类)与效价-唤醒度。
用途:训练大规模FER模型(如LibreFace)。
08 DISFA
特点:27名参与者的自发表情视频,标注AU强度(0-5级)。
作用:验证AU检测模型的细粒度性能。
09 少样本学习(Few-shot Learning)
定义:通过少量示例(如10张标注图像)快速适应新任务(如识别特定文化表情)。
例:Flamingo模型在30例数据下超越传统对比学习模型。
10 情境化情感模型(Contextualized Emotion Model)
定义:结合环境信息(如场景、交互对象)推断情感,突破“面部中心主义”。
例:GPT-4V通过“婚礼场景”修正“微笑”的情感解释。
(全文结束)
部分素材源于网络
如有侵权,请联系删除
END