CxHub客户体验社区-用户研究、体验爱好者学习交流社区,专注客户体验(CX)研究。
社交媒体

对应分析法(同质性分析或数量化方法)是一种探索性多元统计分析方法and一种分析变量间关系的统计技术。
主要用于分析 定类变量 之间的关系。 可视化 地将几组看不出联系的数据,通过二维平面展现出来。
将行、列变量的交叉表变换为一张散点图 ,把表格中包含的关联信息用 散点空间位置关系 的形式表现出来。
另外一种说法就是将交叉表里面的 频数数据作变换 以后,利用散点图方式,直观地解释变量不同类别间的联系。
(无兴趣可忽略)
对应分析的原理在于首先将数据降维,然后将具体数值点投影到维度空间中;维度只是个数学上的概念,并无实际名字意义,通俗理解为将‘关系’浓缩成‘几个维度’,比如将‘差异’关系浓缩成‘2个维度’。绝大多数情况下,对应分析只需要建立2个维度,因为这样只需要投影出一个对应图便于实际分析;如果维度个数超过2个,那么则会出现很多个对应图,这样会加大实际分析的难度。
简单对应分析(CA):两个分类变量间的联系
多重对应分析(MCA):多个分类变量间的联系
均值对应分析:对应分析家族的“异类”
多重对应分析的原理和简单对应分析略有不同,当多重对应分析只分析2个变量时,得到的结果可能和简单对应分析不完全一样,但趋势是一致的。
应用场景非常广泛,以市场研究为例:品牌形象的测定&消费者市场细分研究是较为常见的研究方向。
① 数据类型:基本以无序分类数据为主。
② 假设检验:数据之间有着 差异关系(两两之间具有差异性) 是前置条件,变量纳入前先做 卡方检验,只有具有相关性,才有必要作对应分析。
具体P值的界值为多少才合适并无统一的标准,一般如果P值大于0.2,则没必要进行对应分析;如果在P值在0.05~0.2之间,可以考虑进行对应分析,但对结果的解释仍需要慎重。
③样本量:对 极端值敏感 ,分析时有必要去除频数过少的单元格;对于小样本不推荐使用。
④ 无量纲化:各变量应具有相同的量纲(或者均无量纲)。
⑤控制变量量:变量不要太多,因为只用两维图解释信息损失太多;
多重对应分析的变量数越多,越容易出错,不建议分析太多变量,经验来说一般最多3-4组变量为上限(解释不通时/和TGI有矛盾时减少变量)。
⑥ 谨慎放入变量:需要针对数据含义和业务知识对变量纳入可行性进行初步判断。
① 不能进行假设检验
其本质仍然只是一种描述方法,无法在统计上对变量间联系加以确认。因此在结果解释上需要谨慎,正式分析之前一定要采用卡方检验等方法进行预分析,筛除实际上无关的变量。将得到的图形结果和原始数据反复对照,以确保结论的正确性。
② 不能自动判断最佳维度数
需要研究者对提取的维度数量进行制定。一般提取二维或三维最为常见,能够较好的平衡信息量和易读性,如果解释困难,则需要考虑加入新维度来完善结果解释。
③ 存在数据信息丢失
对应分析输出的图形通常是二维的,这是一种降维的方法,将原始的高维数据按一定规则投影到二维图形上。而投影可能引起部分信息的丢失。
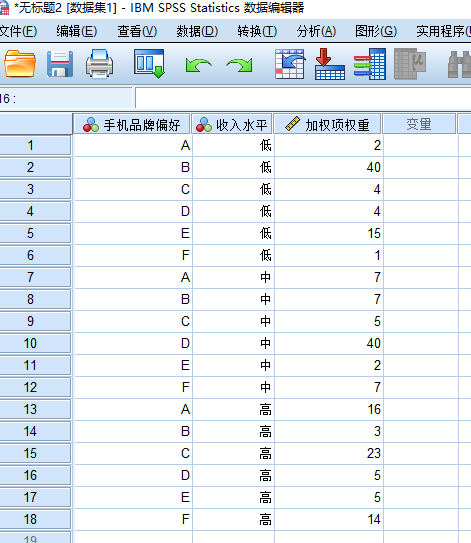
①数据输入及预处理
step1:设置为数值型名义变量
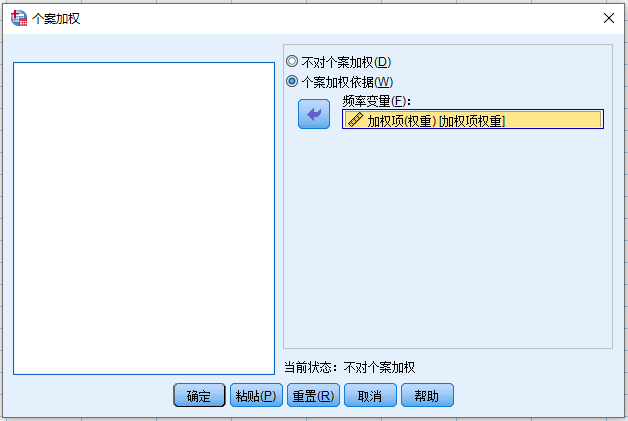
step2:以频数变量进行加权
② 选取分析方法
选择“分析”-“降维”-“对应分析”,定义行/列变量及其取值范围,单击“更新”按钮。
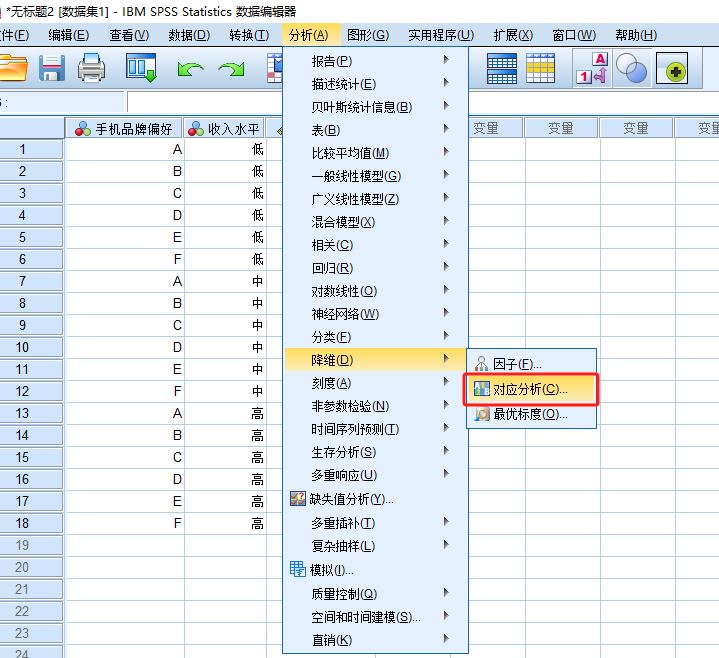
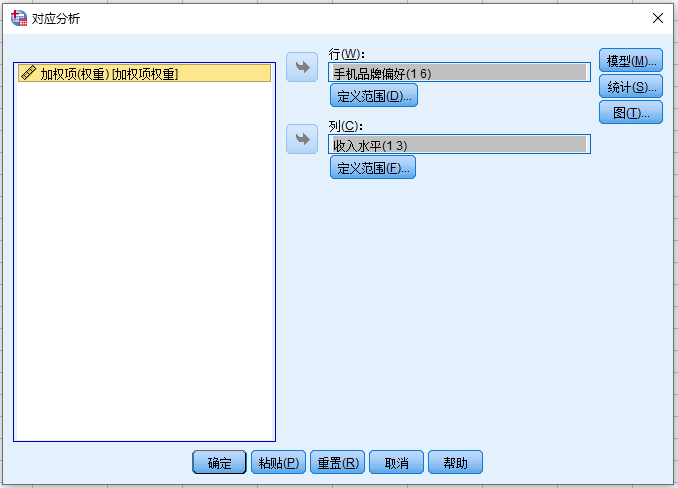
一般默认采取2维,距离测量默认勾选【卡方】。
【卡方】:分类变量的对应分析
【欧氏】:数值变量的对应分析
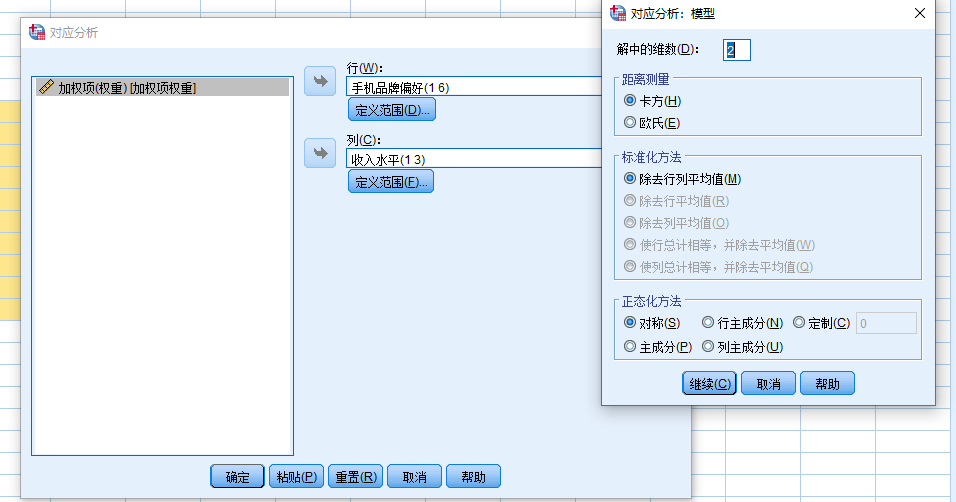
③ 常规参数设置
默认勾选【对应表】【行点概述】【列点概述】
有兴趣可考虑全部都选,多试试
④ 对应分析图参数设置
点击【图】按钮,默认勾选【双标图】
结果分析
①【对应表】
【行】和【列】在不同组合下的实际样本数。
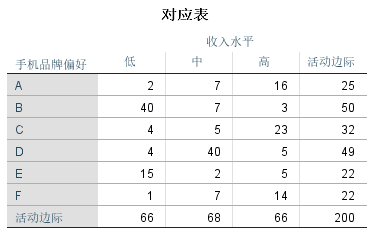
②【摘要】
【维数】:其个数等于变量的最小分类数减1,往往前2~3个维度就已携带绝大多数信息;
【惯量占比】:各个维度所能解释的两个变量关系的百分比,前两个维度就累计解释了100%的信息。
通常情况下累积解释率达80%以上即说明模型非常好
【总计-显著性】:卡方检验结果,显著性小于0.05,说明XXX和XXXX之间存在相关关系,这决定能否继续进行对应分析。
【奇异值和惯量】:奇异值的平方就是惯量;惯量:各维度的结果能够解释两个变量之间联系的程度。
【惯量比例(方差解释比例)】:每个维度的惯量占惯量总和的比例,体现每个维度携带的信息量。
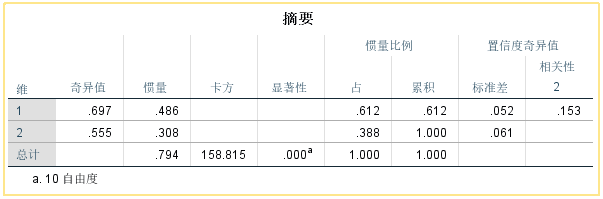
③【概要】
活动边际:表示该行的总计百分比
数量:表示该行个案数目占总个案数目的百分比
活动边际:表示该列的总计百分比
数量:表示该列个案数目占总个案数目的百分比
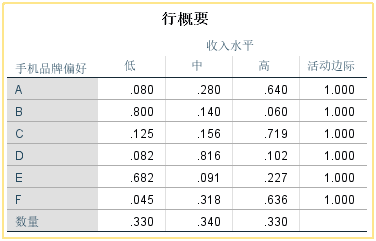
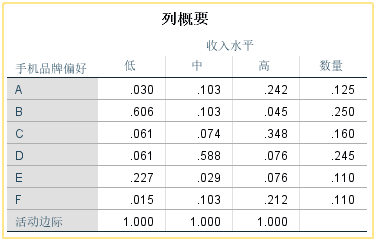
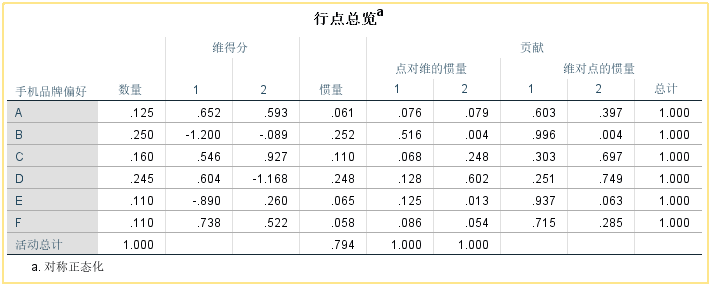
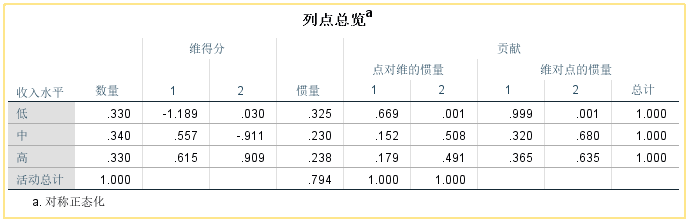
④【总览】
【点对维的惯量】:分类变量中每个类别对维度的贡献,本例中第一维数主要被B/D/E所携带,也就是说这3个类别在第一维数上的区分比较好。
【维对点的惯量】:各类别的信息在各维数上的分布比例,如低收入的信息在第一个维度中占99.9%,第二个维度只有0.1%。
【数量】:各种类别的构成比,如偏好A的人占总数的构成比例是0.125;
【维得分】:行变量和列变量中每个类别在新产生两个维度中的坐标值。
通过这两个表格的数据结果就能够做出对应分析散点图
【惯量】:总惯量(0.794)在行变量中的分解情况,数值越大表示该类别对惯量的贡献越大。
代表对应维度在解释原始数据信息中的重要性
【总计】:各维数的信息比例之和,1表示某一类别在前两维中提取的100%的信息,效果最好。
⑤【对应分析图】
(1)离原点越远,意味着该点对于‘关系幅度’的表达越强,即说明该点越能体现出‘关系’。
(2)点与点之间挨着越近(远),意味着它们之间关联关系越强(弱)。
(3)位于相同象限的不同变量的分类点之间的关联较强。
(4)靠近原点的散点通常没有倾向性,不做解释。
没有差异并不代表不重要,只是没有差异
(5)每个维度可能代表了一种特征:实际上是提取出的主成分,但由于分类变量的信息较少,可能找不到合理的解释。
eg:B/E和低收入,A/C/F和高收入,D和中收入存在着比较强的联系。
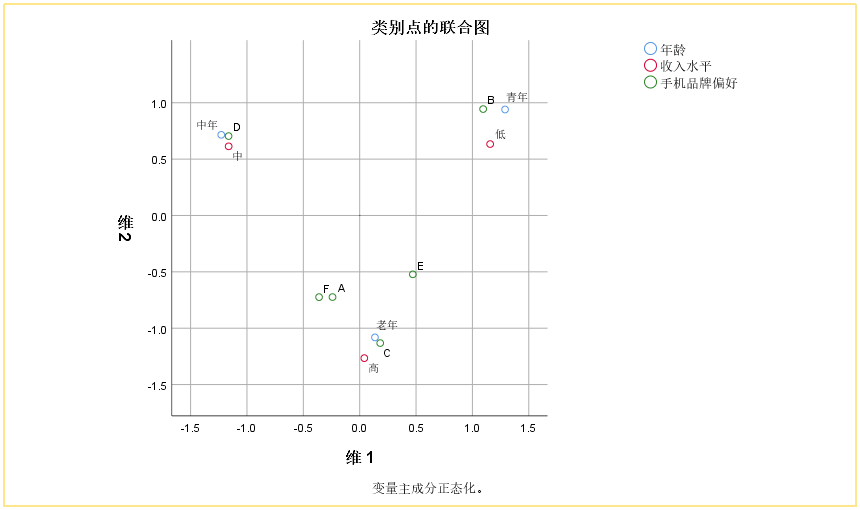
从品牌角度思考,越远离中心的品牌,消费者很容易识别,说明品牌特征越明显,越靠近中心的品牌,消费者不易识别。
简单对应分析中,模型会自动给出卡方检验,但多重对应分析需另外处理
① 根据经验和卡方检验,筛选合适的变量进入模型。
卡方检验此处不做详细说明,需证明两两具有相关性
② 频数加权。
此处同上
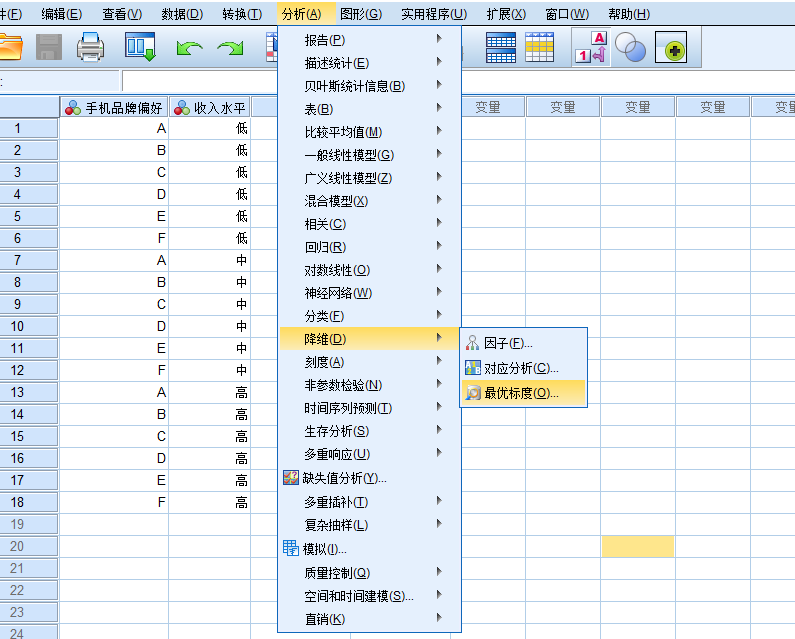
③【分析】-【降维】-【最优标度】
step1:把要分析的三个变量都放在对话框里。解释维度默认是2。
step2:把三个变量都放进联合类别图。
结果分析
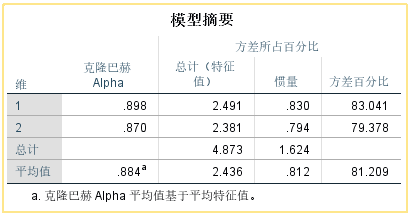
①【模型摘要】
给出了各个维度上的特征值、惯量和解释方差百分比的信息,如第一维度和第二维度上分别可以解释数据变异的83%和79%
这张图可不看:这个模型是经过最优标度变换之后,再把信息投射在两个维度上,由于变换中损失了多少信息不知道,所以再看模型的两个维度携带了多少信息就没有意义了。
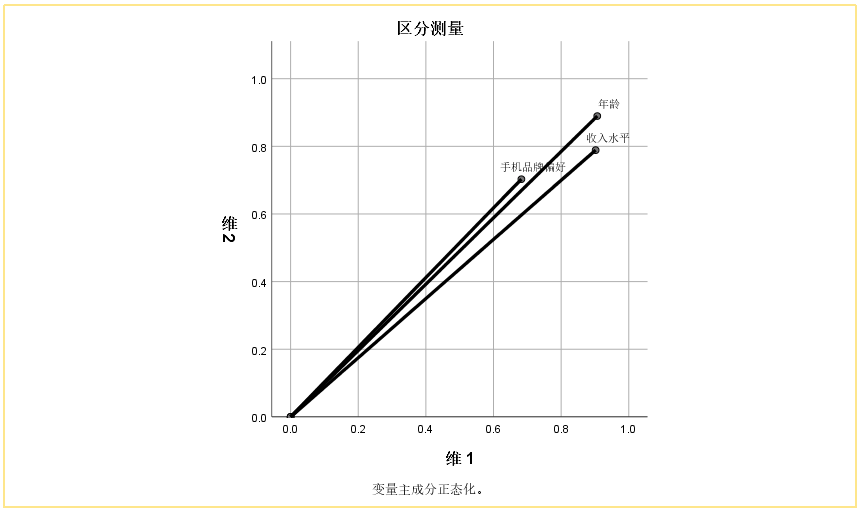
②【区分测量】
三个变量,在两个维度上投射的信息都很多(线段越长,投射信息越多)
假如有的变量在两个维度上携带的信息都很少,即线段很短,可考虑不放入模型。
变量若靠近维2或者维1,意味着不同变量在维度上有高的区分度和分散度。
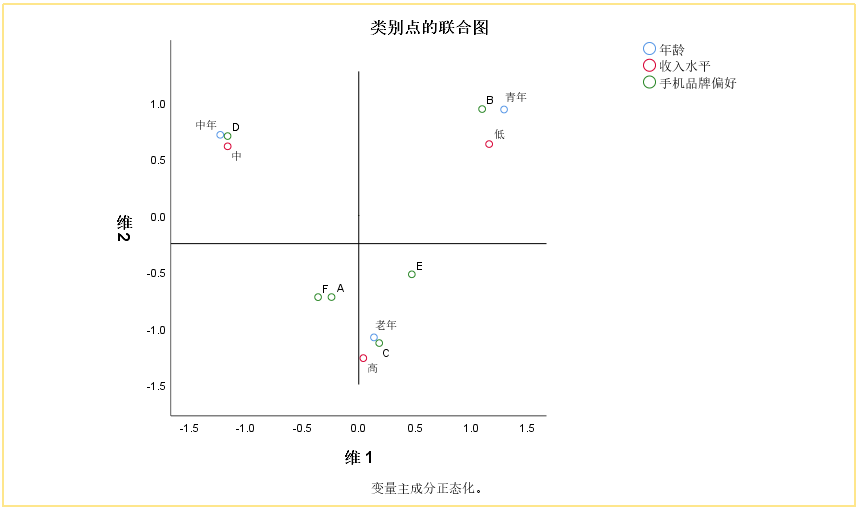
③【联合图】
分析同上
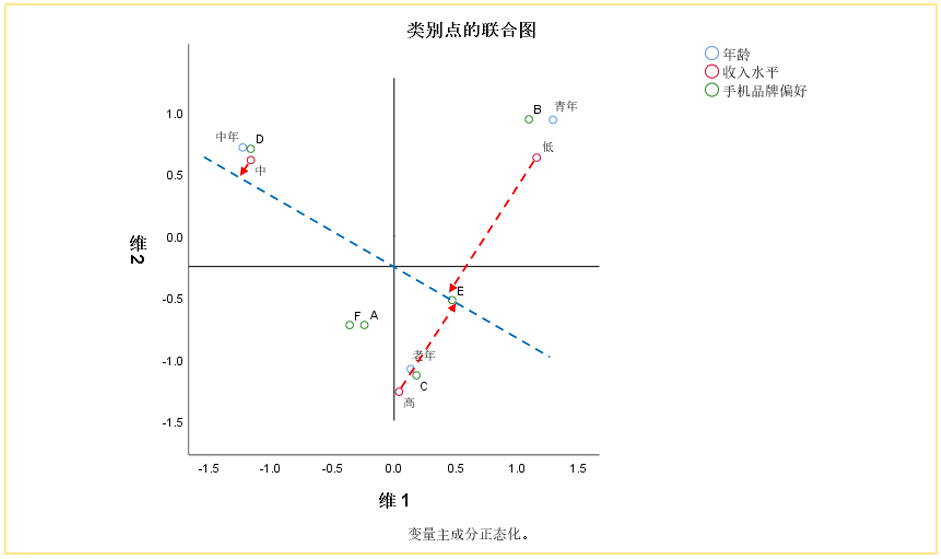
④ 偏好排序
拓展部分,一般用不上
从中心向任意点连线-向量,往这条向量及延长线上作垂线,垂点越靠近向量正向的表示越偏好。
偏好E品牌的依次为中收入、高收入、低收入。
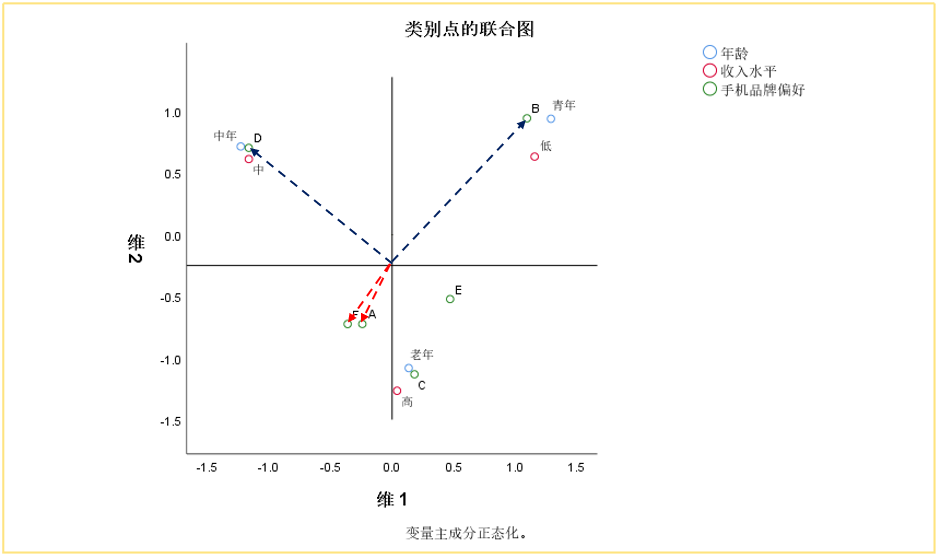
⑤ 属性相似性
向量夹角, 从余弦定理的角度看相似性。
夹角是锐角的话表示两个品牌具有相似性,锐角越小越相似;如果向量是钝角&平角,即为完全不同的品牌。
⑥ 产品定位:理想点与反理想点模型
以E为定位点,以它的利益为半径画圆:越先圈进来的人就是最喜欢这个品牌的消费群,越先圈进来的品牌越可能是竞争品牌,其他同理;

根据对应分析的原理进行扩展应用,对应分析家族中的“异类”。
与简单对应分析一样,都只涉及两个分类变量。
区别:均值对应分析基于定距变量,简单对应分析基于定类变量
① 数据转换
需要将数据转换成表示行、列分类变量相关关系强度的数据
与简单对应分析不同,由于单元格内的数据不是频数,因此不能使用标准化残差来表示相关强度,而只能使用距离来表示相关强度。
举例说明转换过程:
step1:单元格内的数字代表品牌销售数量

step2:通过标准化残差公式,以第一个单元格的数据为例说明转换过程:


step3:通过上述操作就顺利把频数转换为距离(单元格内的数据为连续型数据)
均值对应分析由于涉及数据转换和标准化方式选择,不同的数据标准化方式,最终作出的对应分析图也有很大的差别,应该结合原始数据和对应分析图来对分析结果的优劣做出综合评价。
② 实践操作
以下为原始数据汇总表,与常规的对应分析数据类型不一致
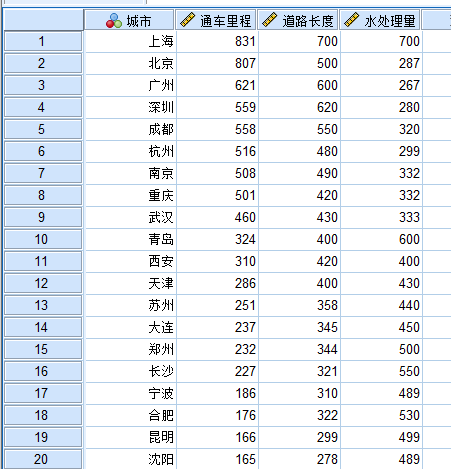
采用Syntax编程语言,将数据读入软件,这种方法简单快捷
step1:【文件】-【新建】-【语法】,输入下面的语句,然后点击运行按钮。
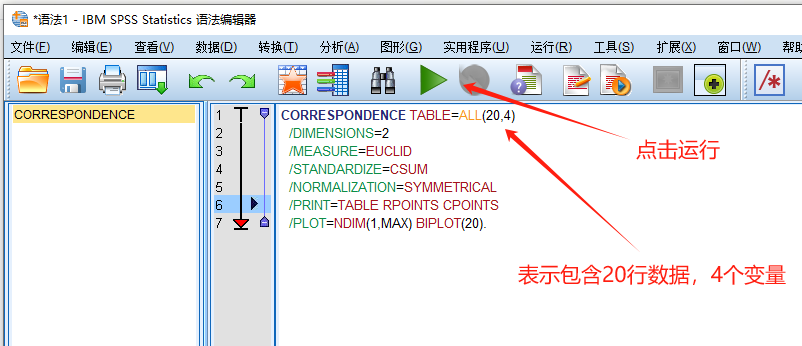
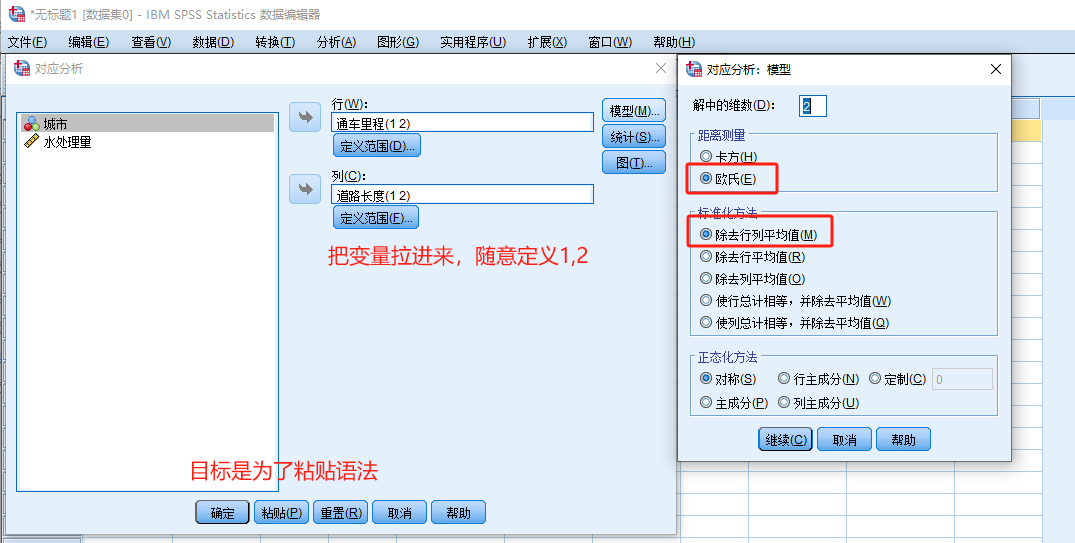
也可以借用简单对应分析的操作步骤,复制并修改代码。
即可省去自己手动编写的功夫。

③ 结果分析
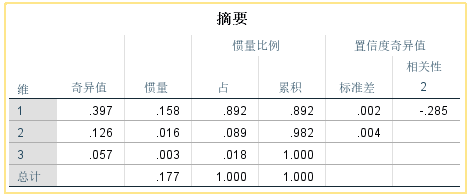
前两个维度总共解释了原始数据信息量的98.2%,因此使用前两个维度就能展示分类变量的作用结果。
通常情况下累积解释率达80%以上即说明模型非常好
如果发现前两个维度信息量太少,可以考虑选择3个(根据数据情况来),修改“解中的维数”,重新分析报告。
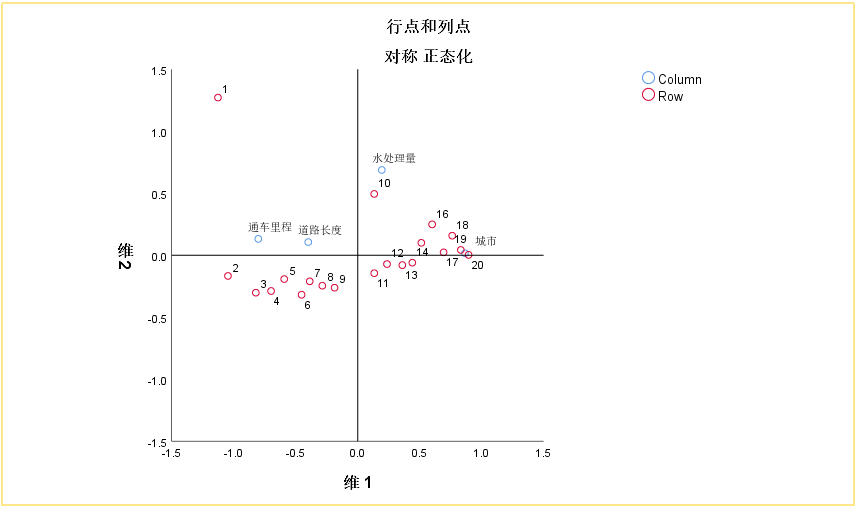
解读:
① 通车里程和道路长度基本相近,水处理量则处在另一象限;
② 城市2-9和城市11-20基本分开为两类城市,可以初步判断两类城市特点不同;
③ 城市1与其他城市明显有差异,返回原始数据看到城市1在三个维度上都是TOP1的数值;
参考文献
① 李沛良 《社会研究的统计应用》
② 陈哲 《活用数据》
③ 郑宗成,陈进《市场研究实务》
④ 张文彤《SPSS统计分析高级教程》
⑤ 王怀亮《R软件在对应分析中应用研究》