CxHub客户体验社区-用户研究、体验爱好者学习交流社区,专注客户体验(CX)研究。
社交媒体

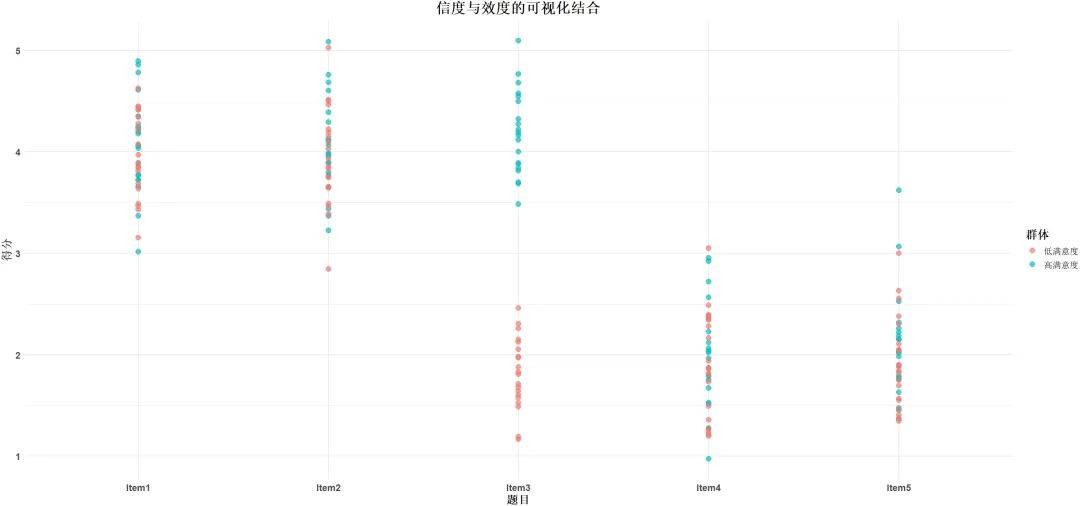
在用户研究领域,“信度”(Reliability)与“效度”(Validity)是衡量研究工具和方法科学性的重要标准,尤其常用于 量表问卷 的编写、校验中。
信度指的是测量的一致性,即在相同条件下重复测量时,能否获得一致的结果。
效度指的是 测量的准确性,即研究工具是否测量了它想要测量的内容 。
举例来说,如果一个用户满意度调查问卷的信度很高,则表明它在不同时间或不同组别中反复测量能获得类似结果;而它的效度很高则意味着它的测量结果确实反映了用户的真实满意度。
温度计的例子:想象一支温度计,用来测量同一杯水的温度。理想情况下,如果测量工具有高信度,那么不管测量几次,温度计都应该给出几乎相同的读数。如果你反复测量,而温度每次都差异很大,这说明温度计的信度低,结果不可靠。信度高就是指,即便在相同的情况下多次使用,该工具的测量结果是一致的。
测体温的例子:一支好的体温计应该准确反映人体的实际体温,这样才能说明它有效。如果它的读数总是偏低或偏高,偏离实际体温,这就说明它的效度不高。因此,效度高的工具不但要稳定一致,还要准确反映所测的“真实”值。
把这两者串起来,用打靶来做比喻。
① 信度高但效度低:每次射击都打在靶的同一位置,但离靶心较远,每次射击结果很一致(信度高),但都没有命中靶心(效度低)。
② 效度高但信度低:如果你的每一发子弹都能落在靶心附近,但分布非常分散,无法精确地聚集到一个点。
③ 信度和效度都高:每次射击都集中在靶心位置,既稳定一致又准确,这样的射击表现即是信度和效度都高。
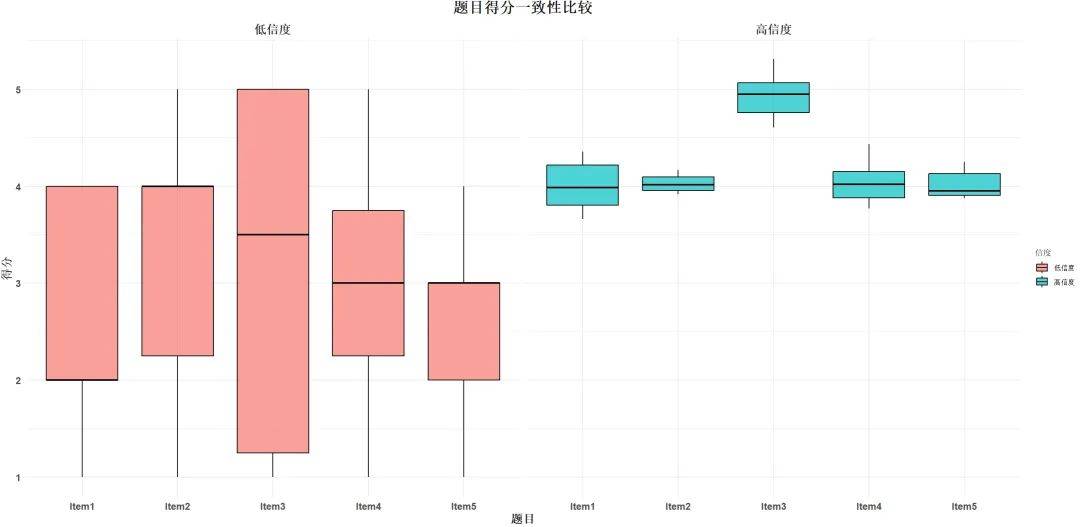
1. 内部一致性信度
定义
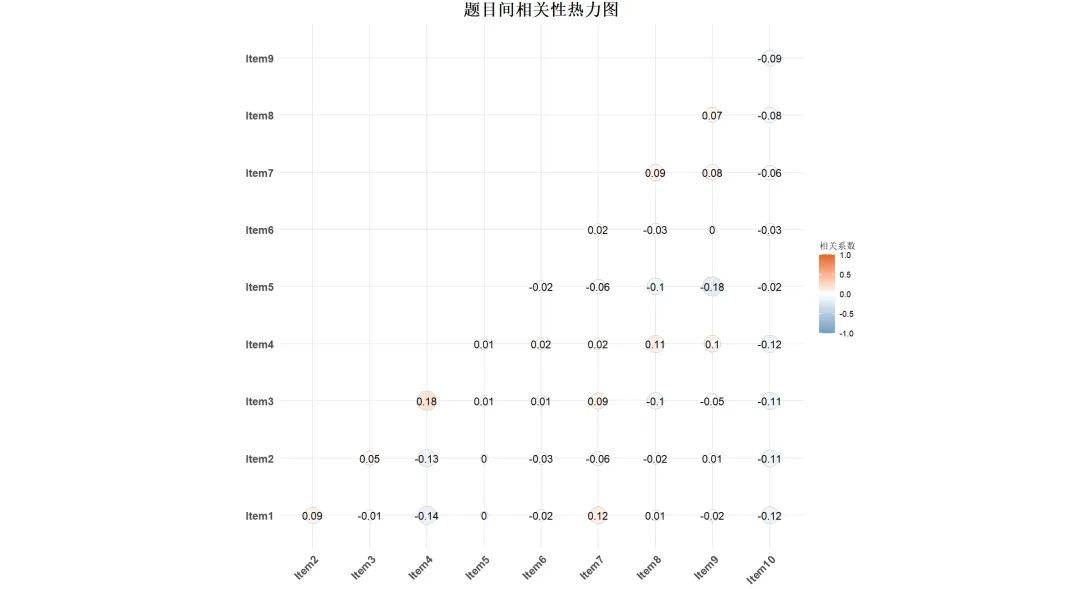
内部一致性信度是指测量工具中 不同项目或题目是否能够一致地测量同一特质 。它通常通过计算 各个题目之间的相关性 来评估。
理论背景
在许多心理学和社会科学研究中,测试通常是由多个题项组成的,内部一致性信度就是评估这些题项是否反映了同一个概念或特征。
常用统计指标
常见的评估内部一致性的方法包括计算 Cronbach's Alpha系数 。Cronbach’s Alpha值越高(接近1),表明工具的内部一致性越强。
Cronbach’s Alpha(克朗巴赫 α 系数):这是评估问卷或量表内部一致性的最常用统计方法,适用于测量工具中各题目之间的相关性。Cronbach’s Alpha值越接近1,表示测量工具内部一致性越高,一般认为0.7以上的值为可接受。
用SPSS即可简单计算,只要样本数量够大,题项数最少不少于三个,基本可以在0.7以上。
例子
在测量用户满意度时,问卷中的多个问题(如“您对产品的外观是否满意?”“您对产品的使用体验是否满意?”)应该反映出同一个概念。如果这些问题之间的相关性很高,则表明问卷具有高内部一致性信度。
2. 重测信度
定义
重测信度是指在相同的被试群体上,使用相同的测量工具在 不同时间点进行测量时 ,测量结果的一致性。
理论背景
重测信度考察的是测量工具在时间上稳定性的能力,确保其在不同时间点能够测量出一致的结果。
理论上,测量工具的信度不仅应在内容上稳定,也应在时间上保持一致。
评估方法
通过计算 重测相关系数 (例如皮尔森相关系数),来评估同一测量工具在两次测量之间的相关性。
通常,相关系数达到0.8或以上,被认为是可靠的。
例子
如果你在一周内两次对同一批消费者进行产品满意度测量,重测信度高的工具将会在两次测量中给出相似的结果。
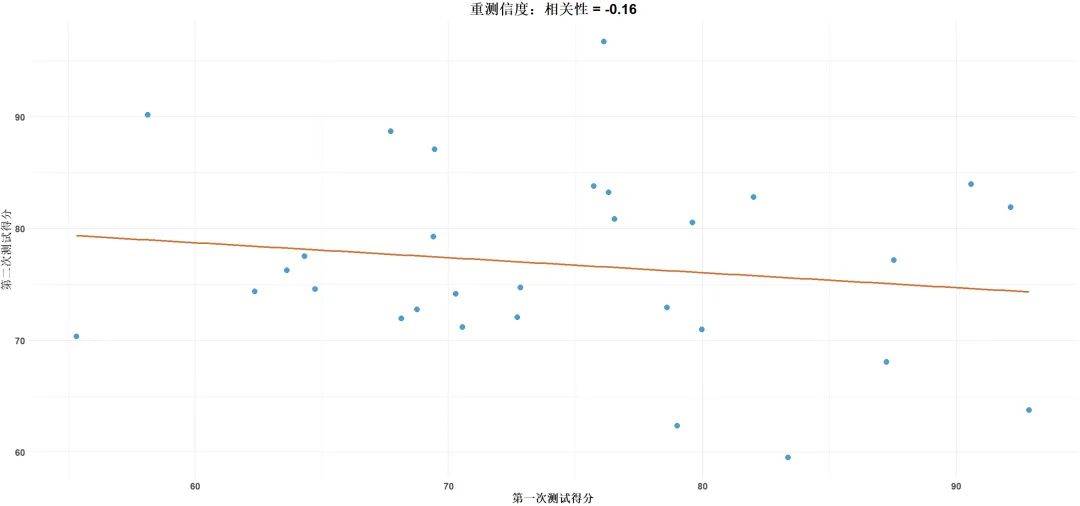
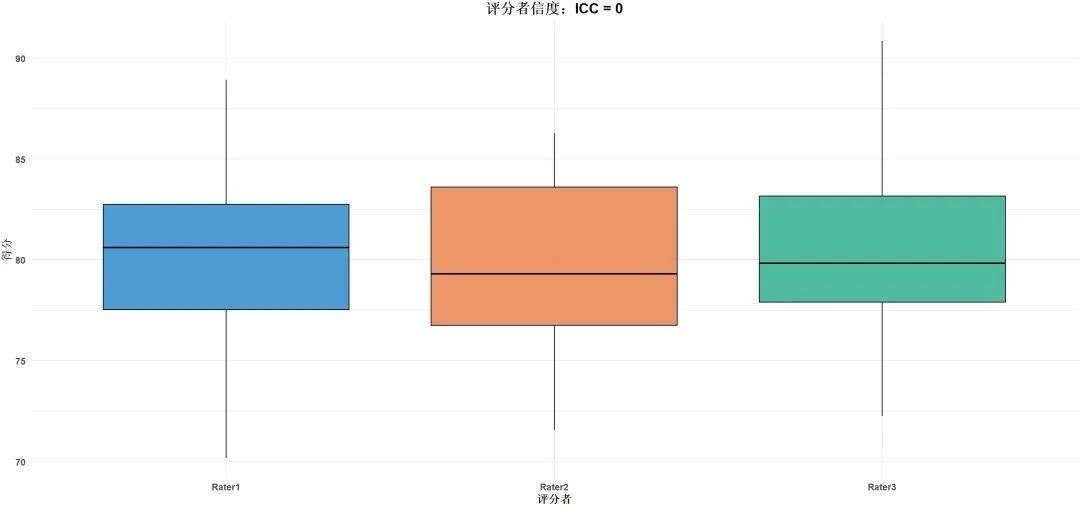
3. 评分者信度
定义
评分者信度指的是 不同评分者 对同一被试或同一测量对象的评分一致性。
理论背景
评分者信度的理论背景源于测量工具的客观性。在一些研究中,尤其是质性研究或观察研究中,评分者信度尤为重要,因为评分者的主观性可能影响测量结果。
评估方法
常见的评估方法包括计算不同评分者之间的相关系数,或者使用 Kappa系数 (Kappa值越接近1,表明评分者之间的一致性越高)。
例子
假设两位研究员分别对10个访谈录音进行情感分析,评分者信度高意味着两位研究员在分析过程中对相同录音的情感判断几乎一致。
在经典测量理论中,效度被定义为测量工具或方法的准确性,或其测量到所希望的特质或概念的程度。
经典测量理论将测量结果分解为“真实分数”和“误差分数”:
① 真实分数:反映了测量的真实值或被试所表现出的真实状态。
② 误差分数:是测量中不可避免的随机误差或系统误差的体现。
在此理论下,效度是指测量结果(观察得分)接近真实分数的程度。当误差成分较小而真实分数占比越高,效度就越高。
1.内容效度
定义
内容效度是指测量工具 是否全面地涵盖了所需测量的内容或领域 。
理论基础
内容效度的理论基础来自测量学中的“全面覆盖性”原理,即测量内容应当全面反映出研究所涉及的概念或主题的各个方面。内容效度评估常通过 专家判断或小组讨论 来实现。
应用
例如,在设计一个测量用户满意度的问卷时,内容效度高的问卷应当涵盖服务质量、产品体验、价格合理性等所有影响用户满意度的主要因素。
2.结构效度
定义
结构效度评估的是测量工具是否能够有效地捕捉或反映出特定概念的内在结构。
理论基础
结构效度的理论基础源于心理学中的“构念效度”理论。将心理或行为测量的概念拆解为可操作的测量变量时, 测量工具应能准确捕捉到该概念的核心特征 。这种效度常使用统计方法,如因子分析来验证测量结构是否符合理论预期。
探索性因子分析是当前使用最广泛的结构效度分析测量方法,可通过SPSS实现。
在因子分析一文中,已经有相应的操作步骤和说明。
应用
例如,品牌忠诚度测量工具如果具有良好的结构效度,它的问卷中“再次购买意愿”“品牌推荐意愿”等题项在统计上应聚成一组,这表明它们确实反映出“忠诚度”这一结构性概念。
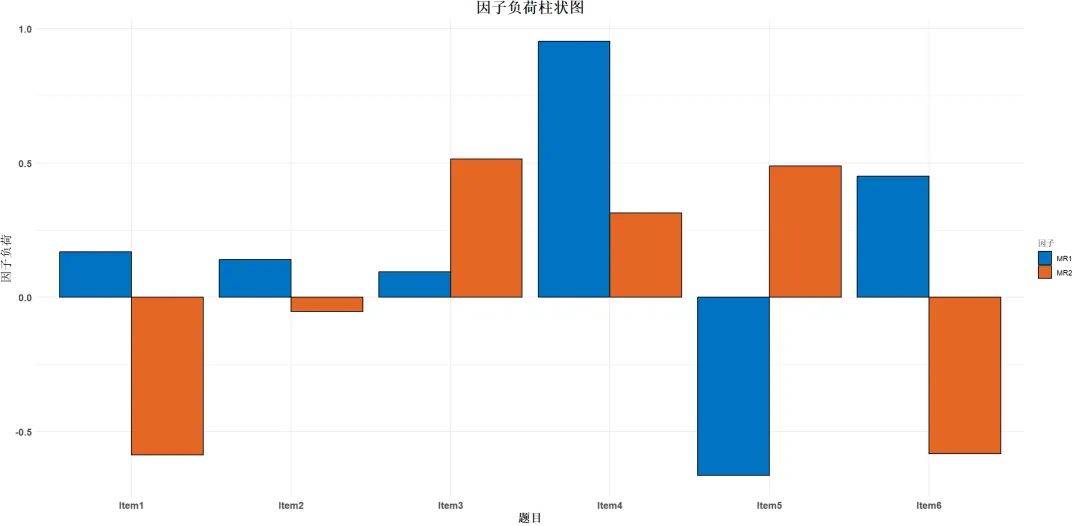
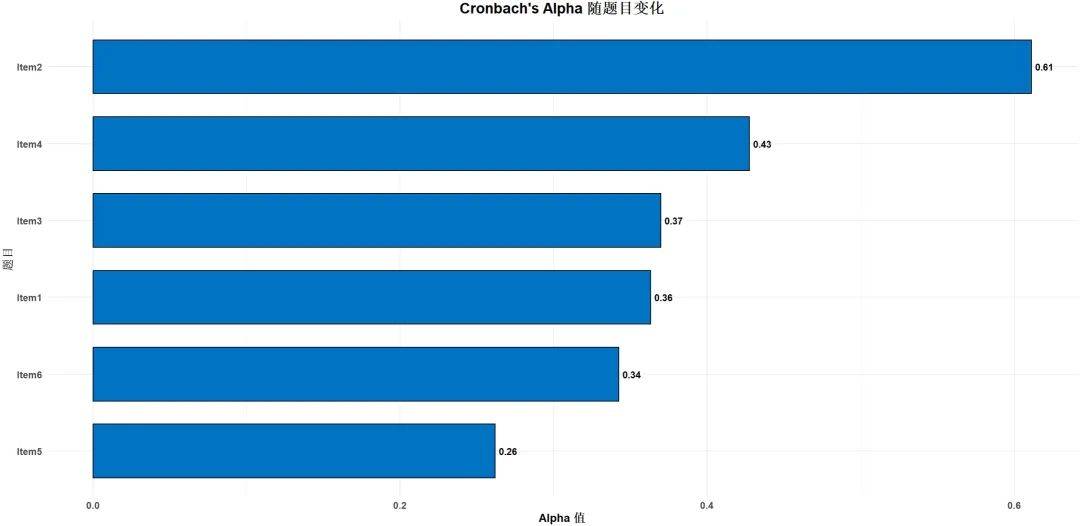
(图片仅供示例)

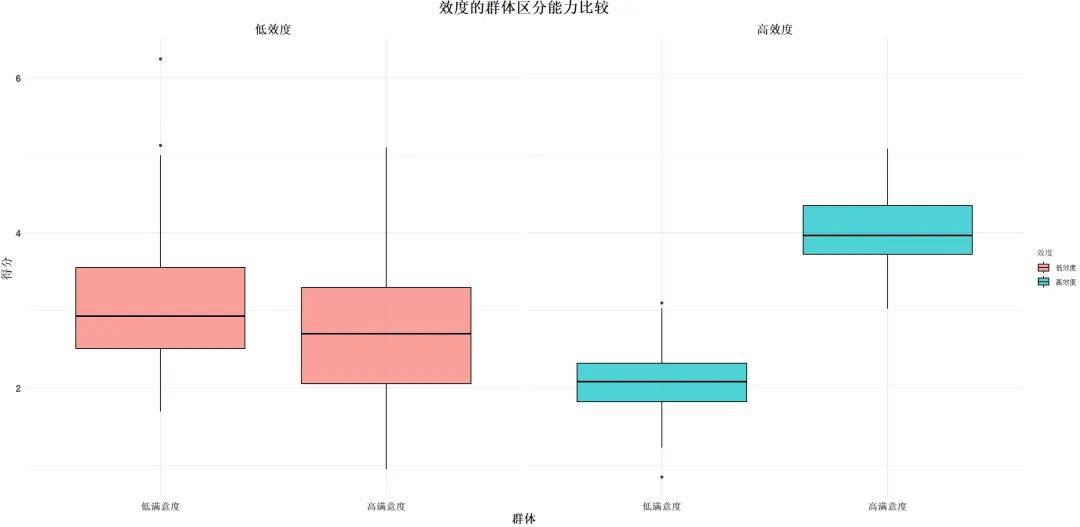
3.效标效度
效标效度,又称“准则效度”,进一步分为同时效度和预测效度。
定义
效标效度评估的是测量结果是否能够 有效地与外部标准(即效标)相关联 。比如,一个测量工具能否准确地与用户实际行为或事件结果相符合。
理论基础
效标效度的理论基础是“ 相关性原则 ”,即测量工具的结果应能够与其所希望预测或解释的外部标准之间存在显著相关性。主要是以下两种:
同时效度:指测量结果是否能与当前的标准相关联。
预测效度:指测量结果是否能够准确预测未来的行为或结果。
应用
比如如果一个客户满意度问卷能够很好地预测客户未来的购买行为(例如满意度高的客户更可能再次购买),那么这个问卷具有较高的预测效度。
效度分析仅仅针对量表/数值型数据,而其他如多选/单选之类的题目不能进行效度分析。
信度:高信度无法保证数据的准确性,例如在用户研究中,如果题目本身设计不合理,哪怕结果一致性高,也不能代表真实的用户意图。
效度:效度的评价有时 依赖主观判断 ,例如内容效度需依赖专家,难以保证客观性。
设计稳定的问题:使用具体且清晰的问题,减少参与者理解的偏差。
增加测量次数:通过重复测试减少随机误差。
训练评分者:标准化评分员培训,减少评分误差。
确保内容全面性:设计前确保所测内容覆盖所有测量维度。
进行试测:在小样本上试测,评估测量的真实相关性。
专家评估:邀请专家检查测量内容的准确性与全面性。