CxHub客户体验社区-用户研究、体验爱好者学习交流社区,专注客户体验(CX)研究。
社交媒体

在数据分析中,处理主观偏差和尺度差异是常见的难题。用户评分习惯的差异(如某些人倾向于给高分或低分)以及不同维度间的数值范围不一致,往往会导致分析结果失真。
上一章探讨了数据标准化的一些方法,本章将通过一个更具整合性和适用性的概念——双向标准化,将行标准化和列标准化结合起来,解决上述问题,使数据在二维矩阵(如用户评分表)中具有全面的可比性和一致性。
文中提到的例子会更偏向品牌研究&满意度研究领域,这些都是双向标准化常见的领域板块。
双向标准化是指对二维数据矩阵的行和列分别进行标准化处理的双层方法。
其核心目的是同时消除以下两类差异:
对象之间的差异:如用户或品牌之间由于主观评分偏好或行为习惯造成的评分不均衡。
特征之间的差异:如不同维度(如品牌属性、产品性能)之间的尺度不一致或评分分布不同。
双向标准化通过两步实现:
行标准化:针对每一行(如用户评分记录),将评分标准化为零均值和单位标准差,消除个体评分习惯的影响。
列标准化:针对每一列(如品牌属性评分),再次进行零均值单位标准差标准化,平衡维度间的差异。
通过行与列的双层标准化,数据能够更客观地反映各品牌或产品的真实表现。
假设我们有以下初始评分表格:
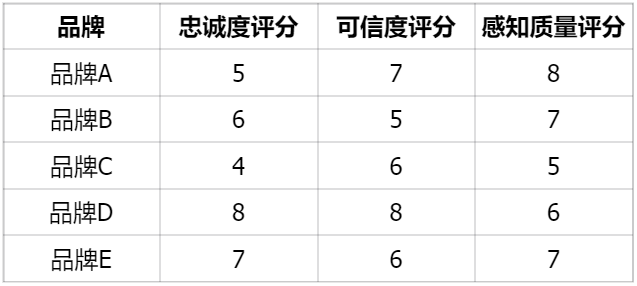
行标准化的目的是消除不同品牌之间评分习惯的差异。
我们先计算每个品牌的均值和标准差,用z-score 标准化公式:

用户1的行标准化:
均值 = (5 + 7 + 8) / 3 = 20 / 3 ≈ 6.67
标准差 = √(( (5-6.67)² + (7-6.67)² + (8-6.67)² ) / 3) ≈ 1.53
行标准化后的评分为:
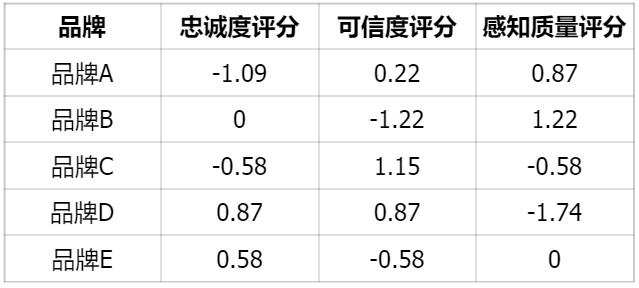
接下来,我们对上表进行列标准化。
以品牌A为例:
均值 = (-1.09 + 0 + -0.58 + 0.87 + 0.58) / 5 ≈ -0.04
标准差 = √((( -1.09 + 0.04)² + (0 + 0.04)² + (-0.58 + 0.04)² + (0.87 + 0.04)² + (0.58 + 0.04)² ) / 5) ≈ 0.77
同样方法对每一列进行标准化,得到最终的双向标准化表:

对于具体计算过程有疑问的,可以查阅上一篇定量数据基础:标准化处理。
解读结果
如果要计算每个维度的平均满意度,可以直接使用双向标准化表中的数据进行平均值计算。这样得到的均值能够更好地反映维度间的相对满意度,因为已经排除了品牌用户评分习惯和维度评分偏见的影响。

双向标准化的计算顺序对结果有直接影响,通常推荐先行标准化再列标准化。
原因如下:
消除用户偏好优先:行标准化首先解决用户评分的主观差异,让数据更客观。
确保维度平衡:列标准化在消除维度差异时,不破坏已校正的用户偏好。
适配分析方法:如 PCA 或回归模型,要求数据维度均衡一致,先行再列的顺序更符合其假设。如果反过来(先列后行),可能导致列间关系被过度调整,影响数据解读。
以下用一个例子来完整地比较先行标准化再列标准化和列标准化再行标准化的两种顺序下的结果。
假设有以下用户对三个品牌(A、B、C)的健康度评分。每行代表一位用户的评分记录,每列代表一个品牌:

从数据可以看出:
用户评分差异:用户1评分普遍较高,用户3评分普遍较低,存在主观偏差。
品牌评分差异:品牌C的评分总体较高,品牌B总体较低,维度间存在分布不一致的问题。
Version 1:先行标准化,再列标准化
step1:行标准化
对每行进行标准化,目标是消除用户评分习惯的差异。公式为:
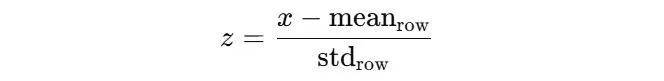

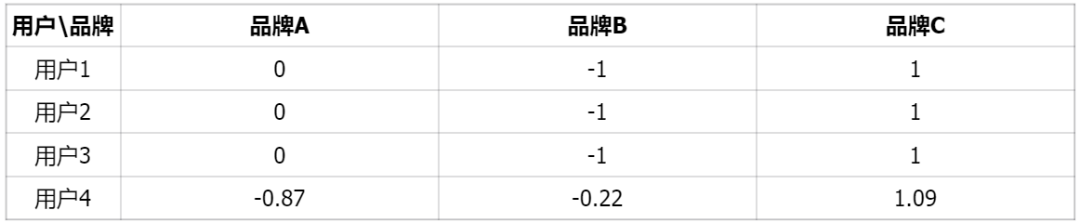
行标准化后的矩阵:
step2:列标准化
对每列进行标准化,目标是平衡品牌之间的评分尺度差异。公式为:
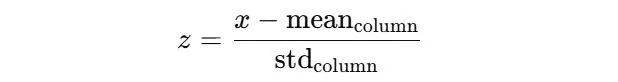
品牌A:

其他品牌类似计算,得到最终矩阵:

Version 2:先列标准化,再行标准化
step1:列标准化
对每列进行标准化,目标是让品牌间的评分分布一致。
品牌A:
其他品牌类似计算,得到:
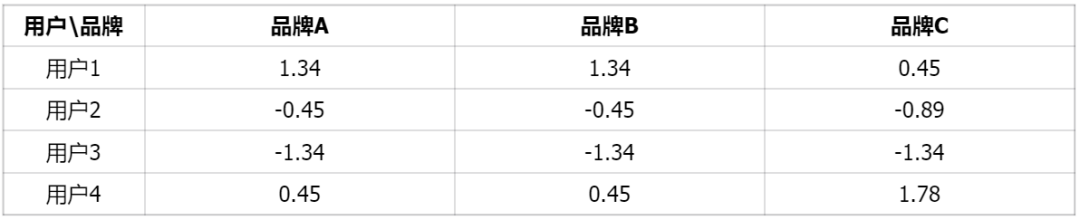
step2:行标准化
接下来对每行进行标准化,目标是消除用户评分习惯的影响。
用户1:
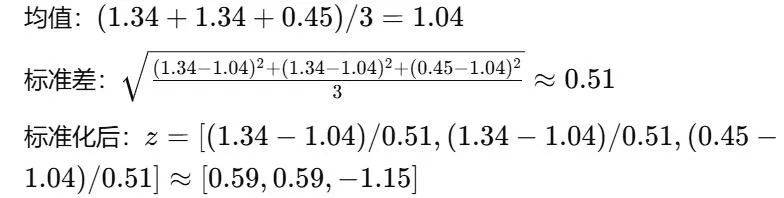
其他用户类似计算,得到最终矩阵:

路径对比与分析
结果差异
先行再列:先调整用户偏好,再平衡品牌差异,得到的结果更关注用户间评分一致性。
先列再行:先调整品牌间的评分差异,再平衡用户偏好,结果更强调品牌间的公平性。
适用场景
先行再列适用于聚焦用户差异的分析,如发现用户群体偏好模式。
先列再行适用于强调品牌比较的场景,如评估品牌间的横向竞争力。
总结一句话:哪个维度更需要对比,那就先做哪种标准化。
双向标准化的优点在于,它让数据既能横向(用户间)对比,也能纵向(特征间)对比,是一种适用于复杂数据场景的强有力方法。它在以下情境中尤为适用:
市场调查和满意度分析:消除用户主观评分偏差,让品牌或产品的实际表现更清晰。
多维数据建模:为聚类分析、主成分分析(PCA)或回归建模提供一致性数据输入。
聚类:使用双向标准化后的数据可以发现用户群体或品牌的潜在分类。
主成分分析:通过 PCA 对品牌的综合表现进行降维分析时,双向标准化确保了各维度在主成分提取中具有相同的权重,避免因某些维度的尺度过大而主导结果。
回归分析:在预测品牌市场表现时,双向标准化可以提高模型的稳定性和准确性,使模型能够公平地评估不同变量对目标变量的影响。
品牌间横向对比:帮助分析多维度下品牌或产品的综合表现。
信息丢失风险:标准化会使数据失去原始单位和直观性,需要结合具体场景解读。
适用场景受限:在数据分布高度均匀或某些特定分析方法中,标准化可能并不必要。
顺序选择的灵活性:根据分析目标的不同,原则上可以调整顺序,但需仔细评估对结果的影响。
双向标准化是数据预处理中的重要工具,能够消除用户评分和维度之间的主观差异,为复杂数据分析提供更清晰、客观的基础。广泛应用在在品牌健康度评估、市场调查和多维度数据建模中。
这一方法的真正价值不仅在于它的数学意义,更在于它帮助我们从混乱的数据中提炼出有价值的洞察,使得复杂问题得以更简单直观地解决。