CxHub客户体验社区-用户研究、体验爱好者学习交流社区,专注客户体验(CX)研究。
社交媒体

接续前章,理解最优尺度回归,得跟线性回归、逻辑回归结合着对比来看。
先举个例子,在具体研究中,会经常遇到不同类型的数据,例如消费者的偏好(定序)、收入水平(定量)和性别(定类)。传统的线性回归难以直接处理定类和定序数据,而最优尺度回归却可以解决这个问题,如何解决,继续往下看。
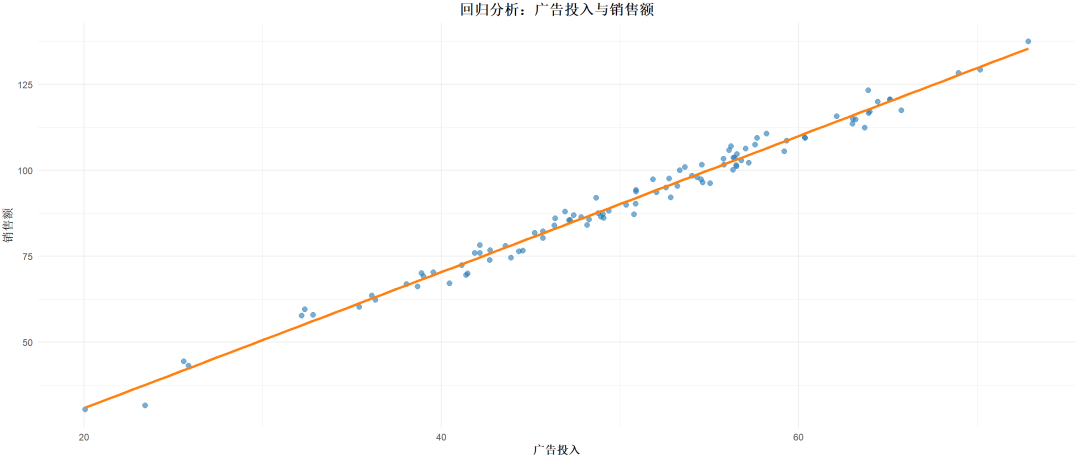
见文拆字,“最优尺度回归”(Optimal Scaling Regression)中的“最优尺度”,在多元统计分析中是一种为了处理非数值数据(如定类数据或定序数据)而发展出来的回归方法。
这里的“最优尺度”是一种数据转换的手段,用来尽可能多地保留原始数据的信息,同时为数据赋予一种“最优”的数值表示,使得转换后的数据能适用于线性回归等数值分析模型。
“最优”的定义主要依据是使得映射后的数值能最大程度地保留原始数据的特征和关系,同时不断缩小预测值和实际值之间的误差,提升线性回归模型对目标变量的解释力或预测精度。
在最优尺度回归中,数据的最优转换通常通过一种反复迭代的算法来实现,不断优化数据的转换方式,使得模型的预测误差最小。
背后的算法核心是交替最小二乘法(ALS)。
以下是其中几个核心步骤:
初始转换:首先对非数值数据进行一种初始转换。比如,对“非常好、好、一般”这样的定序数据,可以先赋予0、1、2这样的数值作为初始值。
回归建模:对转换后的数据构建线性回归模型,计算模型的拟合优度(如R平方值)或者均方误差(MSE)。
尺度调整:根据模型结果,通过优化算法,此时定类变量和定序变量会被重新赋值,使得模型对数据的拟合更优。
迭代优化:重复步骤2和3,直到模型的拟合优度或误差不再显著改善,达到收敛状态。
通过这样的迭代过程,最优尺度回归算法为定类和定序数据找到一个“最优”数值表示,使得数据可以被用于线性回归分析,并达到最佳解释或预测效果。
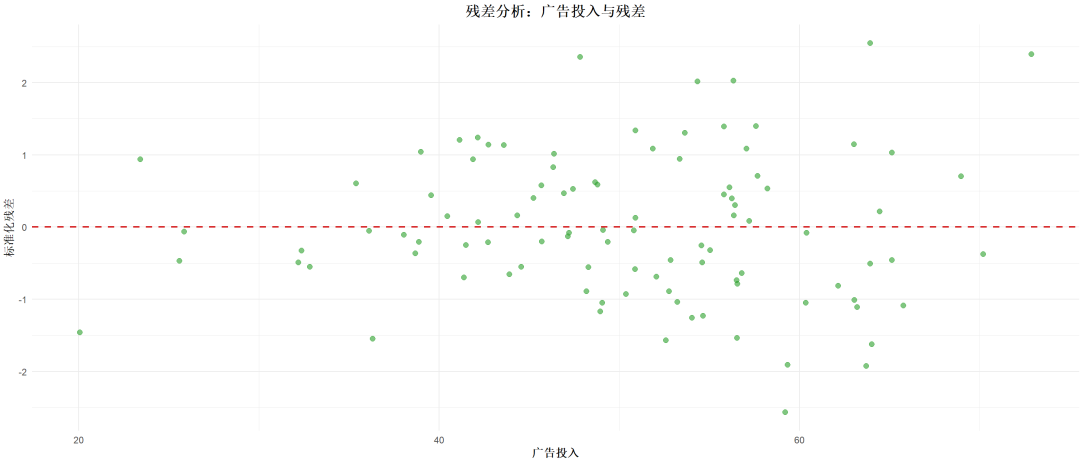
在SPSS中,当你使用最优尺度回归时,实际上是使用了一种自动化回归分析方法,结合了不同的数据尺度转换和模型选择技术。
最优尺度回归的按钮本身并不会提供明确的回归方法选择(如最小二乘法、LASSO等),而是自动根据数据类型和目标回归模型来决定使用何种技术。
这些方法包括普通最小二乘回归(OLS)、多项式回归、广义线性回归(GLM)、偏最小二乘回归(PLS)。
题外话:为何没有明确的回归方法选择?
最优尺度回归的设计是为了简化用户的操作,自动化选择最合适的回归方法。这种方法特别适合于那些对回归分析方法不确定或者对回归技术选择感到困惑的用户。其目标是减少手动调整和选择模型的繁琐步骤,使得回归分析更加智能化和高效化。
自变量和因变量确实适用于所有数据类型,包括定类、定序、定距、以及数值型数据。
适用范围广,能够处理非数值数据,特别适用于多种尺度变量同时存在的情况,但对于连续数据的简单回归任务,传统线性回归更为直接。
灵活性较高,可以适应多种数据类型。
结果依赖于初始转换和迭代算法,可能会存在局部最优问题。
对数据的依赖性较强,最优尺度仅在当前数据集下有效。
在数据量较小的情况下,最优尺度回归的性能可能不如其他线性回归方法稳定。
模型解释性要求较高,尤其是在定类数据较多的情况下,导致解释困难。
过度转换数据变量可能会产生偏差或丢失原始信息。
在SPSS中可以使用CATREG命令执行最优尺度回归,大致步骤如下:
数据准备:确保变量类型设置正确(定类、定序或定量)。
打开分析界面:选择 Analyze > Regression > Optimal Scaling。
变量选择:在界面中将独立变量和依赖变量分别放入相应的框内,并选择适当的尺度。
选择优化参数:在“Options”中选择是否进行因子分析或特定优化。
运行分析:点击“OK”运行最优尺度回归,SPSS将生成结果,包括回归系数、显著性检验和模型拟合度。
结果解读:根据输出的结果表,分析变量间的关系,并检查显著性水平和解释力。
某公司想要了解客户满意度与年龄、性别、收入水平之间的关系。满意度(非常满意、满意、不满意)为定序变量,性别为定类变量,收入和年龄为定量变量。通过最优尺度回归,可以将满意度转化为数值尺度,使模型识别不同变量对满意度的影响程度。
数据:
性别(定类):男、女
年龄(定量):20岁到60岁
收入(定量):1000-10000元
满意度(定序):非常满意、满意、不满意
结果:回归分析显示年龄和收入的系数较大,意味着客户满意度与年龄、收入有较高的相关性。