CxHub客户体验社区-用户研究、体验爱好者学习交流社区,专注客户体验(CX)研究。
社交媒体

本文共 2481 字,预计阅读 7 分钟。TCC 推荐:大家好,这里是 TCC 翻译情报局,我是张聿彤。可用性测试到底需要多少参与者?本文作者经常被问及。由五名参与者进行的可用性研究将发现超过 80% 的界面问题,他介绍得出该结论的依据,并且统计抽样方法也得出了相同结论。5-10 名参与者是一个合理的基线范围,应在每次研究之前进行评估,并附上了需要考虑的一些事项。

我回来了!为沉默道歉。我刚从一场迷失中恢复过来,之前一个月都无法做太多事情。我的身体还未完全恢复,但可以复工和使用电脑了!欢呼!
这个问题是用研人员和利益相关者间存在大量争论的根源 。作为专业人士,我们的目标是可靠性与业务目标及其他影响因素 (例如时间和预算) 之间取得平衡。这意味着我们应识别出不同样本量测试中潜在的风险和影响,并为不同研究项目推荐最佳的小组人数规模……
通常,在不清楚可用性测试内如何及什么环节使用这些用户,用研人员就接受了关于可用性研究流行的人数建议。典型例子是尼尔森 (Nielsen) 的建议:“由五名参与者进行的可用性研究将发现超过 80% 的界面问题”。这个著名的建议基于维尔奇 (1992) 和尼尔森 (1993) 的研究。
根据麦斯菲尔德 (2009) 的说法,他们是这样得出这个结论的:“100 组 5 名用户参加发现界面问题。该研究的确发现,在所有 100 组中发现的问题的平均百分比约为 85%。然而,这个数字有 95 % 的置信水平和 ±18.5% 的误差范围。这意味着对于任何一个特定五人组,发现问题的百分比有 95% 的可能性在 66.5%-100% 的范围内。事实上,一些五人组确实 (实际上) 识别了所有问题; 然而,一个五人组只发现了 55% 的问题。”
最近,福克纳 (2003) 尝试使用统计抽样方法回答同样的问题。她发现,平均而言,尼尔森的预测是正确的。在 100 次模拟测试中测试 5 名用户,发现平均 85% 的可用性问题是在更大的群体中发现的。然而,当仔细查看数据时,由 5 名参与者组成的小组发现的可用性问题的范围从几乎 100% 到只有 55% (类似于早期的研究) 。这对用研人员意味着什么?当我们只依赖 5 名用户时,我们冒着错过几乎一半可用性问题的风险。
回顾福克纳的结果,我们看到增加参与者的数量,可以解决问题并提高研究结果的可靠性。更具体地说,10 名参与者平均可以发现 95% 的问题 (范围从82% 到 100% ) 。参与者增加到 15 名可以平均识别 97% 的问题 (范围为 90% 到 100%) 。

就像用户研究存在诸多方面,没有一种适合所有方面的方法我们可以采用!答案取决于许多因素,应在每次研究之前进行评估。需要考虑的一些因素如下:
根据麦斯菲尔德 (2009) 的评论,可以证明:“对于大多数发现问题的研究,3-20 名用户的小组规模是有效的,5-10 名参与者是一个合理的基线范围,并且小组规模应该随着研究的复杂性和背景的重要性而增加”。

注意: 如果测试质量差,再多用户参与都无济于事……
研究表明,可用性测试的结果很大程度上取决于评估者 (雅各布森和赫茨姆研究,2001) 。例如,使用无效的测试任务或不正确地促进会话。可用性测试中的错误并不少见 —— 即使是有经验的研究人员也会犯错。
正如莫利奇 (2010) 建议的那样,如果我们使用糟糕的方法,无论参与群体的人数规模如何,研究的结果都会很糟糕…… 选择正确的方法并努力防止评估者的错误应该是首要事项。
原文: uxpsychology.substack.com/...
作者: Dr Maria Panagiotidi
译者: 周佳悦
审核:徐曼鹭
编辑:孙淑雅
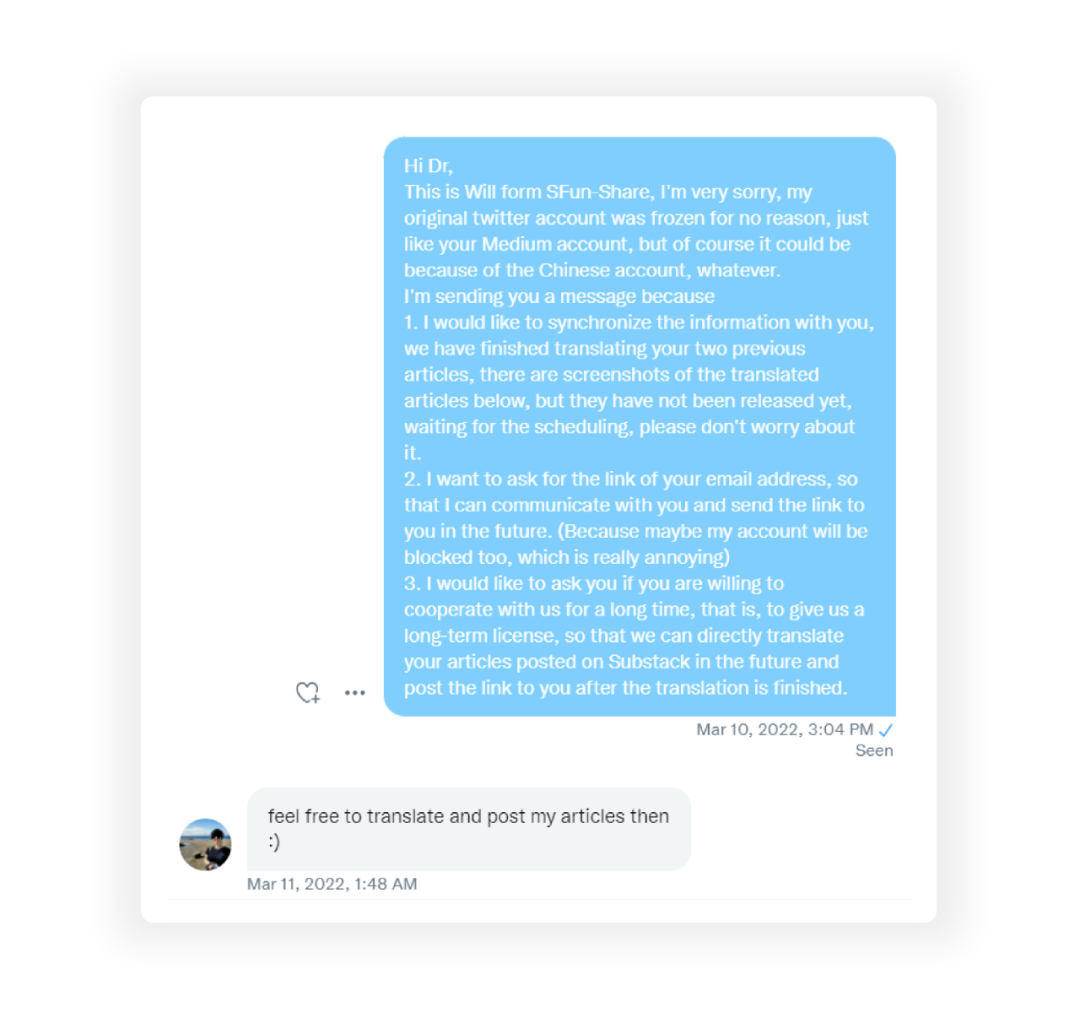
本文翻译已获得作者的正式授权(授权截图如下)