CxHub客户体验社区-用户研究、体验爱好者学习交流社区,专注客户体验(CX)研究。
社交媒体

DBSCAN(Density-Based Spatial Clustering of Applications with Noise)作为一种基于密度的聚类算法,尤其适用于识别用户群体间的自然分层和潜在细分市场。
它能够有效处理任意形状的数据分布和噪声数据。
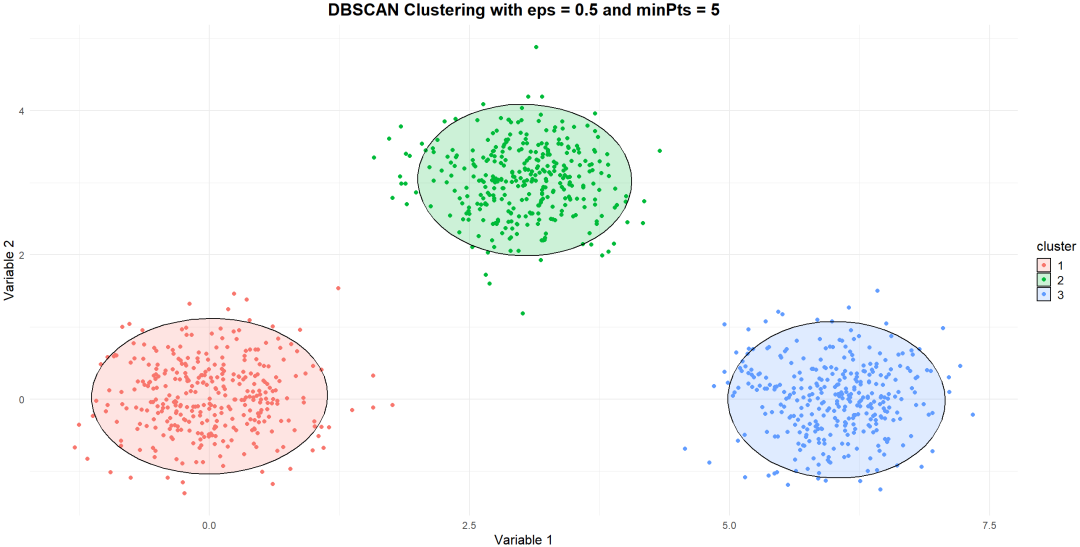
该算法的核心思想是将具有高密度的区域划分为簇,去除噪声。
如何定义高密度?
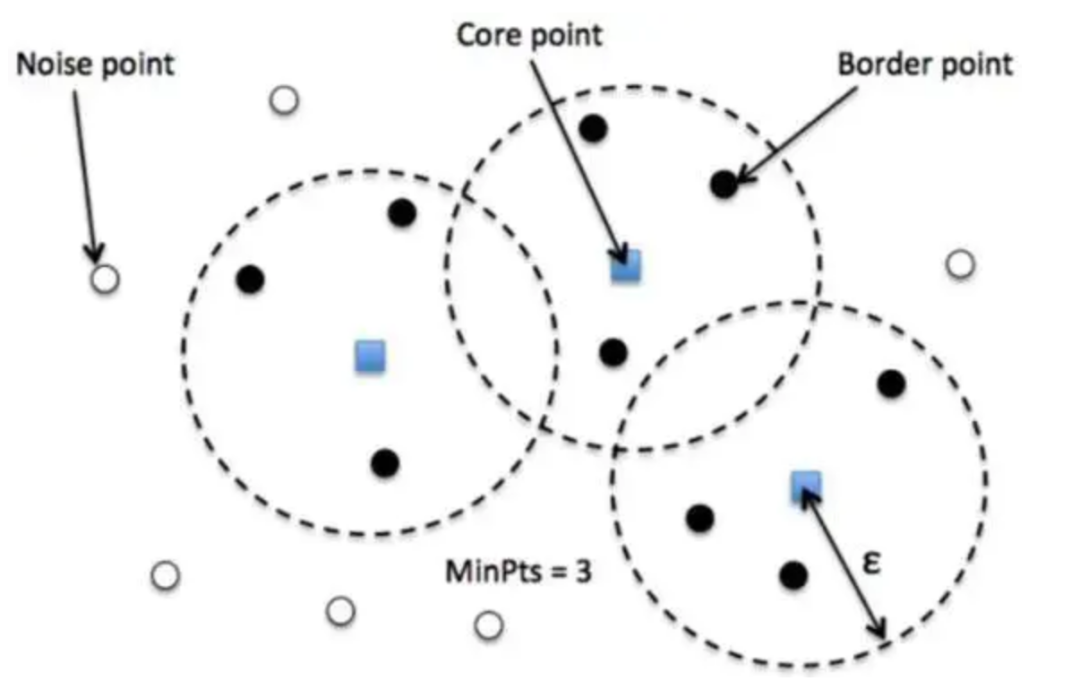
ε(邻域半径): 半径参数,用来定义邻域的大小,即一个点如果在其半径ε范围内存在足够数量的邻居点,则被认为是高密度区域的一部分。
MinPts(最小邻域点数): 表示在一个点周围 ε 范围内的最少点数,只有当这个点的邻域内点数超过 MinPts 才会被认为是核心点。
核心点:在一定半径内(Eps)有足够多(最小点数MinPts)邻居的点;
边界点:在其邻域内少于MinPts个点,但落在某个核心点的邻域内的点;
噪声点:既不是核心点也不是边界点的点。
新的算法正在被提出来,比如OPTICS。
Python:scikit-learn库
R:fpc包(包含了dbscan包)
以下以R为例进行分析,数据为SPSS软件自带数据集。

如何合理设定Eps(邻域半径)和MinPts(最小点数)?
可视化探索
k 距离(即距离该点最近的第 k 个点的距离)随 k 增长的曲线。曲线的拐点或平缓区通常对应合理的Eps值,因为这些位置标志着邻域点数量显著增加或减少。以K-distance图为探索示例

解读:通常选择肘部位置对应的 K-distance 值作为EPS,并根据初始斜率来调整MinPts(较大的斜率可能意味着选择较小的MinPts 值;而较小的斜率则可能需要较大的MinPts 值)。
① 局部密度变化:K-distance 反映了数据点的局部密度。当 K-distance 较小时,意味着数据点附近有较多的邻近数据点,密度较高;而当 K-distance 较大时,意味着数据点附近的邻近数据点较少,密度较低。
② 肘部位置:K-distance 图的“肘部”通常对应着数据集的自然分界点。在肘部附近,K-distance 的变化率会明显减小,表示数据集中存在一个相对明显的密度变化点,可以作为选择 EPS 参数的依据。
③ 密度变化趋势:观察 K-distance 图的整体趋势,可以了解数据集的全局密度分布情况。当 K-distance 图整体上呈现出递增或递减趋势时,可以推断数据集的密度分布特征。
④ 异常点识别:K-distance 图还可以用于识别异常点。通常情况下,异常点的 K-distance 值会较大,因为它们可能远离其他数据点或处于低密度区域。
① 如果数据点分布比较密集,Eps应该设定得较小,以便捕捉到更精细的聚类结构。
② 如果数据点分布比较稀疏,Eps应该设定得较大,以避免将单个数据点误判为噪声。
如果有关于数据分布的先验知识或者业务经验,可以利用这些信息来设定参数。他们不是基于严格的数学证明,而是基于以往的经验、直觉或是一些简单的规则,它们往往能够提供解决问题的有效途径。
① 尝试不同的参数组合:先设定一组初始参数,根据初步聚类结果,观察簇的连贯性和噪声点的分布情况,逐步调整 Eps 和 MinPts ,直至得到满意的结果。
② 网格搜索:设定一个 Eps 和 MinPts 的取值范围,通过网格搜索的方式遍历不同的组合,对每组参数运行DBSCAN,评估聚类效果(如轮廓系数、Calinski-Harabasz指数等),选择最优参数组合。
轮廓系数是一种衡量聚类结果质量的指标,可以帮助确定最佳的聚类参数。尝试不同的参数组合,并计算每个聚类结果的轮廓系数,选择使轮廓系数最大化的参数组合。
① 使用如OPTICS算法生成的可达图,它不需要预设 Eps 和 MinPts ,可以推导出适用于DBSCAN的参数。
另外有文章会专门写这个聚类算法。
② DBSCAN的变体,如HDBSCAN,对参数选择不那么敏感,能够自适应地确定eps值。
HDBSCAN并不直接在CRAN上提供,只能通过其他途径在R中安装,最常见的是从GitHub上安装。需要提前安装了devtools包,但我操作后还是失败了,具体原因不详。

如根据购买频率、平均消费额、购买的商品种类等特征,将顾客划分为不同的细分市场。用于理解需求,定制营销策略。
如结合地理坐标信息,发现高密度的商业热点区域或消费者活动集中区域。
通过市场数据中的异常值和离群点,识别市场中的异常行为,如欺诈检测、价格异常波动等。
分析消费者对不同品牌的认知和感受,以确定品牌在市场中的位置和形象。